为什么要参与这场竞争?“部分宝贵数据被微软独家占有”
2023年无疑是生成式人工智能的关键一年,就在这个4月,一场大模型风暴已经来临:
4月8-9日,华为盘古大模型发布会;4月10日,商汤大模型发布会;4月11日,阿里大模型发布会;4月14日,同花顺AI产品发布会;4月18日,阿里行业类模型发布会……
生成式人工智能进步的速度令人瞠目结舌。仅仅在ChatGPT发布几个月后,新的人工智能就已经再次进化出重大升级——GPT-4拥有了多模态的能力,不仅能看懂文字,也能看懂图片了。与此同时,微软将ChatGPT整合到必应搜索中,同时将GPT-4融入微软365,旨在打破办公套件的行业格局。
没几天,OpenAI首席执行官山姆·阿尔特曼在Twitter上宣布了一条消息:我们正在推出ChatGPT插件,您可以通过安装插件来有效地完成各种任务。我们非常期待看到开发人员创造出来的新东西!
一时间,数百亿、千亿乃至万亿级参数规模的人工智能大模型相继涌现,这场ChatGPT引发的全球大模型竞争趋于日趋激烈,这也意味着其背后的人工智能大模型开始进入市场激烈争夺和技术快速迭代的关键博弈期。而这场大模型的竞争很可能像九十年代PC操作系统的竞争一样,具有“垄断性”的倾向和趋势,一旦输掉竞争,就可能会失掉整个市场。

GPT-4拥有了多模态的能力,不仅能看懂文字,也能看懂图片了
大模型进入博弈期
GPT-4的发布在各个领域引起了巨大的轰动,因为它在人工智能技术中达到了一个新的高度。在某些领域,GPT-4已经显露出了其绝对优势,或者说“AI霸权”。
这里说的“霸权”不是政治学里面的操纵或控制其他国家的地位,类似于之前为人所知的“量子霸权”的说法,即在某一领域产生原有工具远不能及的技术优势。比如应用了GPT-4的Office办公软件,只要人们动动嘴(输入想要的期待),从Word到Excel再到PPT,普通人工可能需要一天完成的工作,人工智能几乎就是一瞬间的事情。更不用提ChatGPT在编程领域及基础文案工作上已经逐步产生可观的生产力了。这将大大降低所谓的“工程师红利”,而未来通过创新产生的竞争力比重将继续增大,节约下来的人工可以解放出更多的创新生产力。能否尽快实现“AI霸权”,会成为未来实现创新性国家的一块重要基石。
GPT-4以及众多生成式人工智能的背后,是人工智能大模型的训练结果。随着如ChatGPT和文心一言逐渐进入应用和商业层面,背后的各个大模型也进入关键博弈期。中国能否在未来数年内推出自己的大模型成为关键。
从参数规模来看,国内已经诞生了能够比肩ChatGPT参数量的大模型。有与美国一拼高下的基础和潜力。而大模型竞争之所以时间紧迫,有这么几个考虑。
大模型竞争同时也是一场市场争夺战。先占领市场、研发排他性强独占性强的优势产品,既是大厂企业的竞争策略,也是优势厂家的竞争结果。目前,谷歌推出类似ChatGPT的大模型Bard之后。谷歌与微软的竞争再起:微软正聚焦在B端(如办公软件、云计算和人工智能相关产品)以及游戏等相关领域,而谷歌则在C端市场、互联网领域推出更多定制化产品。而不管是B端还是C端,对这些优势产品必然有依赖性,这样的依赖性也将是这些产品继续在所处赛道扩大优势的重要方式。
对于那些获得大模型先手优势的企业来说,在这轮竞争中更容易积累“数据雪球”、建立“数据壁垒”。在自然语言处理领域,数据是训练大型语言模型的基础,因此拥有高质量的数据集是非常重要的。以ChatGPT为例,在ChatGPT的发展过程中,通过抢先开始公测并收集用户数据,OpenAI获得了巨大的先发优势。这些数据不仅有助于优化ChatGPT的性能和提升用户体验,还可以用于训练更加先进的大型语言模型,从而扩大数据优势。而这部分宝贵的数据被微软独家占有。
为了持续维护数据壁垒,OpenAI需要不断地投入资金和人力资源进行数据采集、标注和更新。同时不断改进模型算法和优化性能,以确保ChatGPT始终是最好用的自然语言处理类大模型,而只要ChatGPT仍然是最好用的自然语言处理类大模型,这个“雪球”就会越滚越大,其他企业将越来越难追上,从而进一步扩大“雪球”效应,巩固其在市场上的领先地位。
此外,拥有市场和壁垒的企业将进一步对国际标准制定发起进攻。人工智能大模型的国际标准领域,包括模型的设计和开发标准、模型的应用和部署标准、模型的数据隐私和安全标准、模型的伦理和社会责任标准、模型的性能和效果评价标准等等。在某一市场和领域,通过制定国际标准,企业可以获得更广泛的认可和市场份额。特别是对一些排他性的技术、软件和产品,一旦国际标准被确定下来,制定标准者将能够决定市场走向。
就拿模型的数据隐私和安全标准来说,包括模型在数据收集、存储、传输、使用等方面的隐私和安全标准,目的是确保模型对用户数据的隐私和安全有一定的保障,避免出现数据泄露和滥用等问题。而一旦一些大模型拥有了这方面的标准制定权或优势,将更易于将自己的大模型推广出去,成为具有垄断性的产品。
除此之外,如果大模型与应用端的厂家也向国际标准制定发起进攻,很有可能以后一些软件和产品也会出现独特的标准,就像当年微软的office标准OOXML一样。一旦这样的标准出现了,其他大模型连接的产品无法接入,势必就会逐渐败落。
因此未来几年大模型进入关键博弈期,它的市场竞争或许可以参考操作当年微软和苹果、中国与微软系统竞争的经验和教训。
从操作系统之争看大模型之战
之所以说大模型的竞争很可能像九十年代PC操作系统的竞争一样,具有“垄断性”的倾向和趋势,其本质还是在于大模型和操作系统一样,都是一个技术新时代的“基础设施”。如同需要搭乘操作系统的软件一样,所有的人工智能产品,尤其是生成式人工智能,乃至未来可能的通用型人工智能,都需要依靠背后的人工智能大模型才能完成训练、输出等一系列动作。
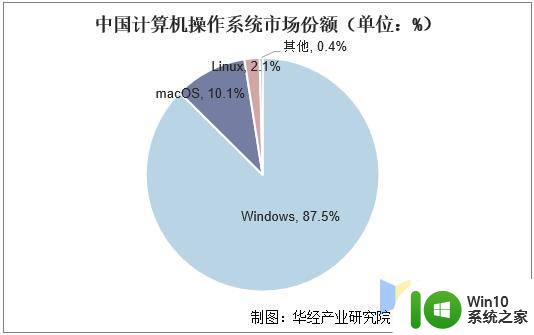
2020年中国计算机操作系统市场份额占比图
而这样的大模型,与操作系统一样具有垄断性的特点。一方面,不管是大模型还是操作系统,它们的竞争都是不同生态之间的竞争。正如中科院院士倪光南所说,操作系统的成功与否,关键在于生态系统,需要能够搭建起完整的软件开发者、芯片企业、终端企业、运营商等产业链上的各个主体。大模型也是同样的道理,一个优秀的大模型也将会建立起一套排他性强、独占性强的生态系统。
另一方面,一旦某一个大模型或操作系统占领了市场,它将获得相对于其他后来者无可比拟的优势。这既是由于人们对于生态系统产生路径依赖,也是源于大模型的数据特点,优秀的大模型将能吸引到更多数据,滚起“数据雪球”。而这样的大模型,也将成为人们唯一选择和依赖的大模型,最终形成对于大模型的依赖,后来者很难再通过同样的路径对其进行赶超。
大模型的出现、争夺过程、以及失利之后的惨痛后果,或许都可以从九十年代到二十一世纪初的操作系统之争中找到。
首先,先发者不一定制人,但争霸即是巅峰。而如操作系统的称霸之于软件的压倒性作用一样,大模型的争霸,很有可能导致整个应用端的生态变成“零合竞争”的战场。与大模型的出现一样,当年微软的Windows3和苹果的Macintosh,是两个划时代的同类产品之间的竞争。
1984年,苹果的Macintosh正式发布,这是第一款图形化操作系统。但在当时,Macintosh由于兼容性太差,售价过高,市场反响平平。1990年,微软也推出了自己的图形化操作系统——Windows 3。凭借此前积累的众多用户,该系统一经推出,就得到了迅速推广,占领了Macintosh的市场。
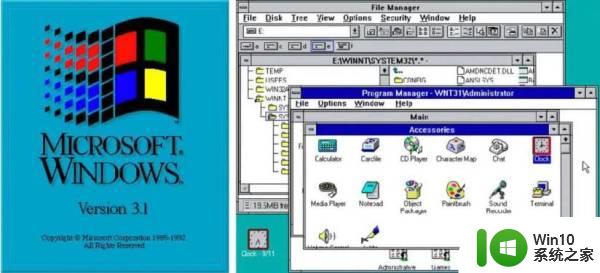
微软靠Windows3赢得了操作系统霸主地位
从此,微软奠定了操作系统的霸主之位。而对应的,苹果的PC机市场份额从这一年开始迅速下降。结果就是苹果输掉操作系统之争,整个市场被微软垄断。在确立了操作系统一哥的地位之后,微软背靠庞大的用户群体,迅速模仿出了大多数盈利且重要的软件产品,并后发制人,一点点蚕食了各大软件公司的市场。
其次,自立自强也有关键节点,时间上永远是现在,领域上永远是底层生态的构建。曾经在操作系统领域,中国也存在“必须拥有自主知识软件操作系统”的共识。但失一城而丢千地,当年没能拿下操作系统竞争的主动权,也导致了互联网发展的长期被动局面。二十一世纪初,中国本想以国产自主研发的操作系统向国际巨头发起挑战,即红旗Linux,曾经也是响彻一时,但最终遭遇“大溃败”。
2002年,红旗宣布与国产办公软件永中合作,将红旗Linux和永中Office联合销售。但永中office、金山WPS等国产软件均基于Linux,这也意味着他们与微软Office有兼容性问题。但2006年,微软的Office国际标准(OOXML)通过后,立马显著提升了它在软件领域和生态构建方面的优势。最终到来的是微软在全球包括中国市场压倒性的胜利,国产桌面操作系统最终日渐式微。
把握关键期,决胜大模型
与操作系统之争失算一样,如果中国在大模型领域失利,好的话像苹果一样落后十年,逮到一次机会再卷土重来;不好的话可能就会像操作系统领域的中国一样,完全没有自主研发系统,直到下次变革机会。而一旦人工智能大模型领域由其他国家主宰,或者是缺少自主研发的产品,可能会引发更为严重的问题,面临在关键领域被“卡脖子”的风险。
正因如此,把握好人工智能大模型的关键博弈期至关重要。国产人工智能大模型,如百度的文心一言,虽然在中文领域展示了自然语言处理与多模态生成的诸多亮点,但就用户体验而言,文心一言的表现不算惊艳。
包括文心一言在内,目前国产大模型与美国的国际顶尖大模型相比仍然有一定的差距,涵盖数据训练、算法等方面。但恰恰是落后的时候,要直面差距、接受批评、迎头赶上。自2020年起,中国的大模型数量骤增,仅2020年到2021年,中国大模型数量就从2个增至21个,和美国量级同等,大幅领先于其他国家。未来,不管是政府还是资本方面,都应给予大模型研发相关的企业和机构更多的支持和宽容,共同推进中国人工智能大模型的发展。
中国应从国家战略科技力量的整体高度出发,组成优势互补的产业协同组合。发挥科研机构在关键核心技术上的研究优势,同时发挥大型科技企业在产品化、工程化、场景化、商业化和数据化方面的优势,成为大模型技术攻关和应用的龙头。以大型科技企业+重点科研机构为龙头,通过开源、合作、众包和生态的创新模式,引导高校、科研机构和创新型企业形成多个技术路线的创新生态群。
《2022中国大模型发展白皮书》指出,以大模型为生态基座的产业链将成为智能化升级中可大规模复用的基础设施。中国大模型厂商在模型布局方面较为完善,接下来应进一步围绕行业赋能的广度和深度持续探索,不断夯实基于大模型的产品建设,推动大模型技术从实验室走向大规模落地。
人工智能大模型正在不断升级迭代,推出包括交通、能源、金融、医疗等一系列应用大模型,实现与产业的深度融合。一方面进一步利用数据这个生产要素,提升我国企业数字化和智能化转型的比例,推动产业数字化进程;另一方面,也将为行业产业降本增效,创造出新需求、新商业模式和新的经济增长点。
为什么要参与这场竞争?“部分宝贵数据被微软独家占有”相关教程
- 刘典:为什么要参与这场竞争?“部分宝贵数据被微软独家占有”
- 玩家起诉微软收购动视被驳回 法官称微软独占COD没好处
- “严重担忧”市场竞争被破坏,英国反垄断部门或调查亚马逊和微软
- 微软限制(竞争对手的 AI)使用 bing 搜索数据
- 微软总裁:中国将成为ChatGPT主要竞争对手
- 微软Edge浏览器遭竞争对手联合投诉,或面临欧盟调查:竞争激烈升级,市场格局生变
- 微软据悉威胁搜索引擎竞争对手:新推AI工具不得使用必应数据库,否则限制访问
- 参与微软年货节互动,赢取珍贵丑毛衣!
- 微软要退出中国?国家数据局组建的背后深意
- 微软计划最早明年推出手机游戏商店,与苹果和谷歌竞争
- 微软推 AI 模型 MAI-1 与 OpenAI 竞争,问界正式回应山西追尾事故,美空军部长亲自体验 AI 战斗机 | 极客早知道
- 英国监管机构初步认定:微软收购动视暴雪将有碍市场竞争
- 全球债市遭抛售,恒指或创新高,马士基业绩超预期
- 高通骁龙8至尊版发布,性能媲美桌面处理器,决胜AI时代的关键!
- 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 一个印度人救了微软,另一个毁了IBM?探讨印度人在科技行业的影响力
微软新闻推荐
- 1 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 2 英特尔AMD史诗级合作,捍卫X86生态:两大巨头联手,颠覆传统CPU格局
- 3 微信消失在桌面了,怎么找回 微信桌面快捷方式消失怎么恢复
- 4 打印机的纸怎么放进去 打印机纸盒放纸技巧
- 5 onedrive开始菜单 Win10如何设置Onedrive开启和使用
- 6 台式电脑如何连接打印机设备打印 台式电脑如何设置本地打印机
- 7 惠普笔记本win11移动硬盘怎么用 win11系统移动硬盘插入后不显示
- 8 微软称每天有超过15000条恶意QR码信息被发送到教育目标,如何有效应对?
- 9 win10系统电脑没有wifi选项 Win10无线网络不显示解决方法
- 10 win7能看见的文件夹win10看不到 win7可以访问win10但win10无法访问win7
win10系统推荐
- 1 系统之家ghost win10 64位稳定家庭版下载v2023.06
- 2 系统之家win10 64位旗舰破解版v2023.06
- 3 雨林木风ghost win10 32位家庭版正版v2023.06
- 4 雨林木风ghost win10 32位官方安装版v2023.06
- 5 电脑公司ghost win10 32位精简优化版v2023.06
- 6 电脑公司ghost win10 64位官方安全原版v2023.06
- 7 深度技术ghost win10 32位最新破解版v2023.05
- 8 电脑公司win10 64位旗舰安全版v2023.05
- 9 电脑公司ghost win10 32位免费安装版v2023.05
- 10 萝卜家园ghost windows10 32位稳定游戏版下载v2023.05
系统教程推荐
- 1 蜘蛛侠:暗影之网win10无法运行解决方法 蜘蛛侠暗影之网win10闪退解决方法
- 2 win10玩只狼:影逝二度游戏卡顿什么原因 win10玩只狼:影逝二度游戏卡顿的处理方法 win10只狼影逝二度游戏卡顿解决方法
- 3 U盘装机提示Error 15:File Not Found怎么解决 U盘装机Error 15怎么解决
- 4 《极品飞车13:变速》win10无法启动解决方法 极品飞车13变速win10闪退解决方法
- 5 window7电脑开机stop:c000021a{fata systemerror}蓝屏修复方法 Windows7电脑开机蓝屏stop c000021a错误修复方法
- 6 win10桌面图标设置没有权限访问如何处理 Win10桌面图标权限访问被拒绝怎么办
- 7 win10打不开应用商店一直转圈修复方法 win10应用商店打不开怎么办
- 8 无线网络手机能连上电脑连不上怎么办 无线网络手机连接电脑失败怎么解决
- 9 win10错误代码0xc0000098开不了机修复方法 win10系统启动错误代码0xc0000098怎么办
- 10 笔记本win10系统网络显示小地球只有飞行模式如何恢复 笔记本win10系统网络无法连接小地球图标灰色