微软大模型WaveCoder!2万个实例数据集,提升LLM泛化能力
用高质量数据集进行指令调优,能让大模型性能快速提升。

对此,微软研究团队训练了一个CodeOcean数据集,包含了2万个指令实例的数据集,以及4个通用代码相关任务。
与此同时,研究人员微调了一个代码大模型WaveCoder。

论文地址:https://arxiv.org/abs/2312.14187
实验结果表明,Wavecoder优于其他开源模型,在以前的代码生成任务中表现出色。
指令调优,释放「代码大模型」潜力
过去的一年,GPT-4、Gemini、Llama等大模型在一系列复杂NLP任务中取得了前所未有的性能。
这些LLM利用自监督预训练的过程,以及随后的微调,展示了强大的零/少样本的能力,能够有效遵循人类指示完成不同的任务。
然而,若想训练微调这样一个大模型,其成本非常巨大。
因此,一些相对较小的LLM,特别是代码大语言模型(Code LLM),因其在广泛的代码相关任务上的卓越的性能,而引起了许多研究者的关注。
鉴于LLM可以通过预训练获得丰富的专业知识,因此在代码语料库上进行高效的预训练,对代码大模型至关重要。
包括Codex、CodeGen、StarCoder和CodeLLaMa在内的多项研究已经成功证明,预训练过程可以显著提高大模型处理代码相关问题的能力。
此外,指令调优的多项研究(FLAN、ExT5)表明,指令调优后的模型在各种任务中的表现符合人类预期。
这些研究将数千个任务纳入训练管道,以提高预训练模型对下游任务的泛化能力。
比如,InstructGPT通过整合人类标注者编写的高质量指令数据,有效地调整了用户输入,推进指令调优的进一步探索。
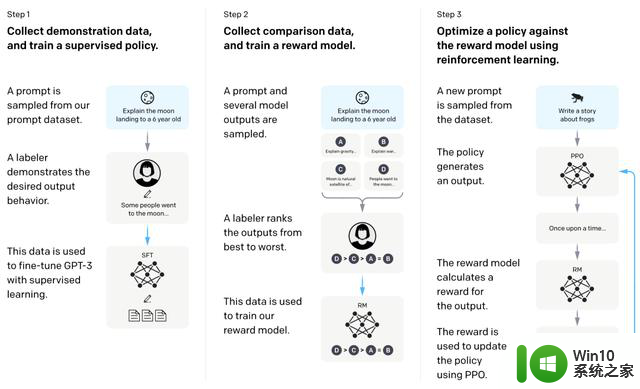
斯坦福的Alpaca利用ChatGPT通过Self-Instruct的方法,自己生成指令数据,进而用于指令调优的过程。
WizardLM和WizardCoder则应用了evol-instruct的方法,进一步提高了预训练模型的有效性。
这些近来的研究都体现了,指令调优在提高大模型性能方面,展现出强大的潜力。
基于这些工作,研究人员的直觉是,指令调优可以激活大模型的潜力,然后将预训练模型微调到出色的智能水平。
对此,他们总结了指令调优的主要功能:
- 泛化
指令调优最初是为了增强大模型的跨任务泛化能力而提出的,当使用不同的NLP任务指令进行微调时,指令调优可提高模型在大量未见任务中的性能。
- 对齐
预训练模型从大量token和句子层面的自监督任务中学习,已经具备了理解文本输入的能力。指令调优为这些预训练模型提供了指令级任务,让它们能够从指令中提取原始文本语义之外的更多信息。这些额外的信息是用户的意图,能增强它们与人类用户的交互能力,从而有助于对齐。
为了通过指令调优提高代码大模型的性能,目前已有许多设计好的生成指令数据的方法,主要集中在两个方面。
例如,self-instructe、vol-instruct利用teacher LLM的零/少样本的能力来生成指令数据,这为教学数据的生成提供了一种神奇的方法。
然而,这些生成方法过于依赖于teacher LLM的性能,有时会产生大量的重复数据,便会降低微调的效率。
CodeOcean:四项任务代码相关指令数据
为了解决这些问题,如图2所示,研究人员提出了一种可以充分利用源代码,并明确控制生成数据质量的方法。
由于指令调优是为了使预训练模型与指令遵循训练集保持一致,研究人员提出了一个用于指令数据生成的LLM Generator-Disciminator(大模型生成器-判别器)框架。
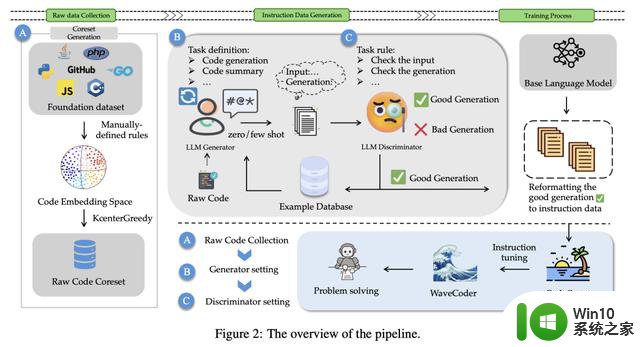
通过使用生成器和判别器,最新方法可以使数据生成过程,更可定制和更可控。
该方法以原始代码作为输入,选择核心数据集,通过调整原始代码的分布,可以稳定地生成更真实的指令数据,控制数据的多样性。
针对上述挑战,研究人员将指令实例分类为4个通用的代码相关任务:代码汇总、代码生成、代码翻译、代码修复。
同时,使用数据生成策略为4个代码相关的任务生成一个由20000个指令实例的数据集,称为CodeOcean。
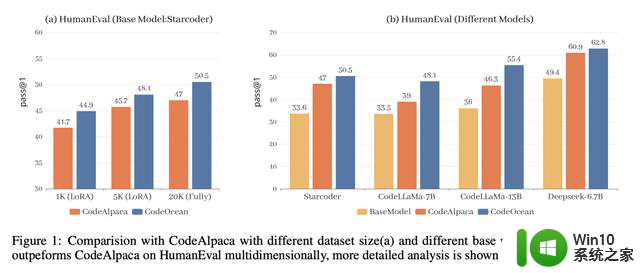
为了验证最新的方法,研究人员将StarCoder、CodeLLaMa、DeepseekCoder作为基础模型。根据最新的数据生成策略,微调出全新的WaveCoder模型。
与此同时,研究人员在 HumanEval、MBPP、HumanEvalPack对模型进行了评估,结果表明,WaveCoder在小规模指令调优的基准上拥有出色的性能。
代码数据生成
如上所述,研究人员选择了4个具有代表性的编码任务,并从开源数据集中收集原始代码。
以下具体介绍了训练数据生成过程。
在本节中,我们将介绍我们探索的方法细节。我们首先选择4个代表性的编码任务,并从开源数据集中收集原始代码。
对于每个任务,作者使用GPT-3.5-turbo生成指令数据进行微调。生成提示如表2所示。

如下,是LLM Generator-Disciminator整体架构,也是数据生成的完整过程。
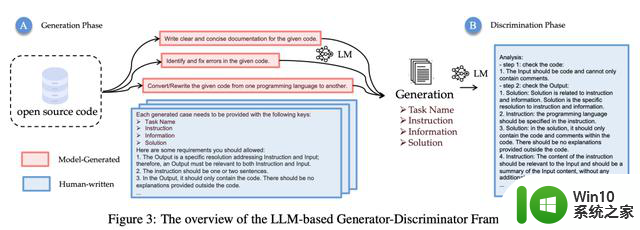
Codesearchnet是一个包含来自 GitHub 上托管的开源库的200万对(注释、代码)的数据集。它包括6种编程语言的代码和文档。我们选择 CodeSearchNet 作为我们的基础数据集,并应用基于 coreset 的选择方法KCenterGreedy来最大化原始代码的多样性。
具体来说,生成器根据输入(a)生成指令数据。随后,判别器接受输出并生成分析结果,输出(b)包括四个键,研究人员将这些信息作为指令调优的输入和输出。
分析(c)包括每条规则的详细原因和总体答案,以检查样本是否满足所有要求。

实验评估结果
代码生成任务评估
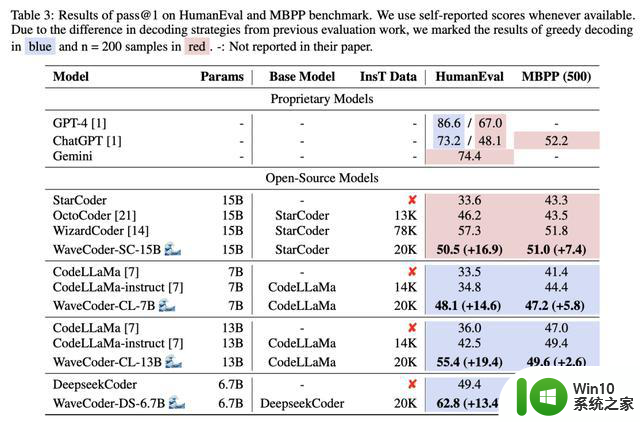
表3显示了两个基准上不同大模型的pass@1得分。从结果来看,我们有以下观察结果:
WaveCoder大大优于使用少于20k指令调优数据(InsT Data)的指令模型训练。
经过微调过程,与基础模型和开源模型的选择相比,最新模型的性能显示出实质性的改善,但它仍然落后于专有模型的指导模型训练超过70k的训练数据。
研究人员还用HumanEvalPack上最先进的Code LLM对WaveCoder进行评分,如表4。
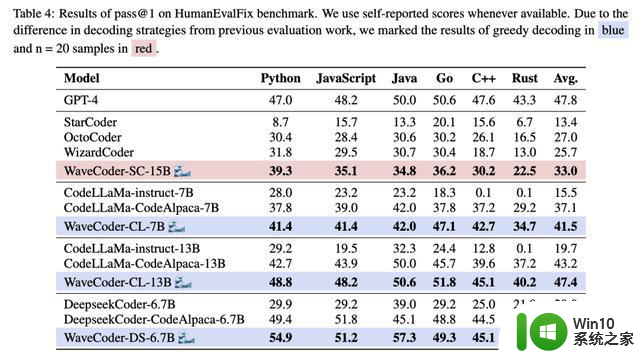
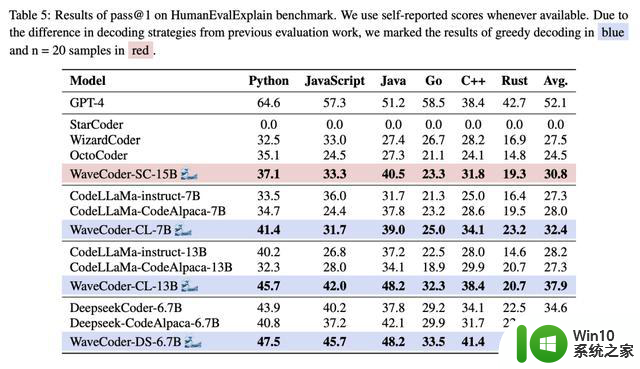
表5列出了WaveCoder在代码汇总任务方面的结果,突出显示了以下显著的观察结果:
参考资料:
https://arxiv.org/abs/2312.14187
微软大模型WaveCoder!2万个实例数据集,提升LLM泛化能力相关教程
- 微软放大招,Microsoft Excel 集成Python,轻松实现数据处理与分析
- 6款大学生爱用的windows软件,个个功能强大,助力学业提升
- 重大争议!微软是否将中国个人数据收集到境外?
- 微软中国成功落地第一个案例:OpenAI催生万科新管理模式
- 微软宣布推出Microsoft 365 Copilot:AI助力生产力大提升
- OpenAI 发布大模型 GPT-4;微软将推进1万人裁员计划
- 比ChatGPT更强大,微软推出全能型人工智能模型Kosmos-1
- 微软市值2.89万亿美元,盖茨展望未来智能模型
- 微软900亿血赚!GPT-4模型搜索能力优于谷歌
- AMD Radeon 800M核显性能提升25%:力拼RTX 2050,游戏性能大幅提升
- 微软高层破例发内部信回应微软苏州大裁员:毫无根据
- 微软举办峰会,大模型赋能网安行业,AI赋能成信息安全胜负手
- 全球债市遭抛售,恒指或创新高,马士基业绩超预期
- 高通骁龙8至尊版发布,性能媲美桌面处理器,决胜AI时代的关键!
- 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 一个印度人救了微软,另一个毁了IBM?探讨印度人在科技行业的影响力
微软新闻推荐
- 1 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 2 英特尔AMD史诗级合作,捍卫X86生态:两大巨头联手,颠覆传统CPU格局
- 3 微信消失在桌面了,怎么找回 微信桌面快捷方式消失怎么恢复
- 4 打印机的纸怎么放进去 打印机纸盒放纸技巧
- 5 onedrive开始菜单 Win10如何设置Onedrive开启和使用
- 6 台式电脑如何连接打印机设备打印 台式电脑如何设置本地打印机
- 7 惠普笔记本win11移动硬盘怎么用 win11系统移动硬盘插入后不显示
- 8 微软称每天有超过15000条恶意QR码信息被发送到教育目标,如何有效应对?
- 9 win10系统电脑没有wifi选项 Win10无线网络不显示解决方法
- 10 win7能看见的文件夹win10看不到 win7可以访问win10但win10无法访问win7
win10系统推荐
- 1 系统之家ghost win10 64位稳定家庭版下载v2023.06
- 2 系统之家win10 64位旗舰破解版v2023.06
- 3 雨林木风ghost win10 32位家庭版正版v2023.06
- 4 雨林木风ghost win10 32位官方安装版v2023.06
- 5 电脑公司ghost win10 32位精简优化版v2023.06
- 6 电脑公司ghost win10 64位官方安全原版v2023.06
- 7 深度技术ghost win10 32位最新破解版v2023.05
- 8 电脑公司win10 64位旗舰安全版v2023.05
- 9 电脑公司ghost win10 32位免费安装版v2023.05
- 10 萝卜家园ghost windows10 32位稳定游戏版下载v2023.05
系统教程推荐
- 1 蜘蛛侠:暗影之网win10无法运行解决方法 蜘蛛侠暗影之网win10闪退解决方法
- 2 win10玩只狼:影逝二度游戏卡顿什么原因 win10玩只狼:影逝二度游戏卡顿的处理方法 win10只狼影逝二度游戏卡顿解决方法
- 3 U盘装机提示Error 15:File Not Found怎么解决 U盘装机Error 15怎么解决
- 4 《极品飞车13:变速》win10无法启动解决方法 极品飞车13变速win10闪退解决方法
- 5 window7电脑开机stop:c000021a{fata systemerror}蓝屏修复方法 Windows7电脑开机蓝屏stop c000021a错误修复方法
- 6 win10桌面图标设置没有权限访问如何处理 Win10桌面图标权限访问被拒绝怎么办
- 7 win10打不开应用商店一直转圈修复方法 win10应用商店打不开怎么办
- 8 无线网络手机能连上电脑连不上怎么办 无线网络手机连接电脑失败怎么解决
- 9 win10错误代码0xc0000098开不了机修复方法 win10系统启动错误代码0xc0000098怎么办
- 10 笔记本win10系统网络显示小地球只有飞行模式如何恢复 笔记本win10系统网络无法连接小地球图标灰色