视觉ChatGPT来了,微软发布,代码已开源
机器之心报道
编辑:陈萍、小舟
Visual ChatGPT 将 ChatGPT 和一系列可视化基础模型连接起来,以支持在聊天过程中发送和接收图像。
近年来,大型语言模型(LLM)取得了令人难以置信的进展,尤其是去年 11 月 30 日,OpenAI 重磅推出的聊天对话模型 ChatGPT,短短三个月席卷社会各个领域。ChatGPT 会的东西五花八门,能陪你聊天、编写代码、修改 bug、解答问题……
但即便是非常强大的 ChatGPT 也存在短板,由于它是用单一语言模态训练而成,因此其处理视觉信息的能力非常有限,相比较而言,视觉基础模型(VFM,Visual Foundation Models)在计算机视觉方面潜力巨大,因而能够理解和生成复杂的图像。例如,BLIP 模型是理解和提供图像描述的专家;大热的 Stable Diffusion 可以基于文本提示合成图像。然而由于 VFM 模型对输入 - 输出格式的苛求和固定限制,使得其在人机交互方面不如会话语言模型灵活。
我们不禁会问,能否构建一个同时支持图像理解和生成的类似 ChatGPT 的系统?一个直观的想法是训练多模态对话模型。然而,建立这样一个系统会消耗大量的数据和计算资源。此外,另一个挑战是,如果我们想整合语言和图像以外的模态,比如视频或语音,该怎么办?每次涉及新的模态或功能时,是否有必要训练一个全新的多模态模型?
来自微软亚洲研究院的研究者提出了一个名为 Visual ChatGPT 的系统来回答上述问题,他们将 ChatGPT 和多个 SOTA 视觉基础模型连接,实现在对话系统中理解和生成图片。为了方便复现,该研究已经将代码完全开源。

论文地址:https://arxiv.org/pdf/2303.04671.pdf
项目地址:https://github.com/microsoft/visual-chatgpt
他们不是从头开始训练一个新的多模态 ChatGPT,而是直接基于 ChatGPT 构建 Visual ChatGPT,并结合了各种 VFM。为了弥合 ChatGPT 和这些 VFM 之间的差距,该研究提出了一个 Prompt Manager,其支持以下功能:
1)明确告诉 ChatGPT 每个 VFM 的功能并指定输入输出格式;
2) 将不同的视觉信息,例如 png 图像、深度图像和 mask 矩阵,转换为语言格式以帮助 ChatGPT 理解;
3) 处理不同 VFM 的历史、优先级和冲突。
在 Prompt Manager 的帮助下,ChatGPT 可以利用这些 VFM,并以迭代的方式接收它们的反馈,直到满足用户的需求或达到结束条件。
总结而言,本文贡献如下:
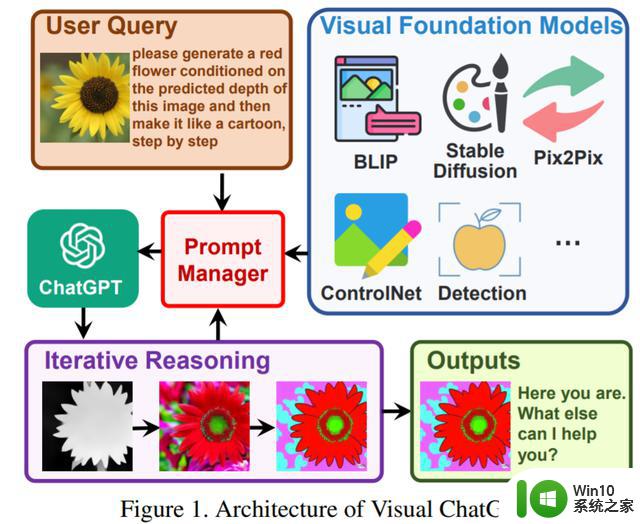
提出 Visual ChatGPT,打开了 ChatGPT 和 VFM 连接的大门,使 ChatGPT 能够处理复杂的视觉任务;设计了一个 Prompt Manager,其中涉及 22 个不同的 VFM,并定义了它们之间的内在关联,以便更好地交互和组合;进行了大量的零样本实验,并展示了大量的案例来验证 Visual ChatGPT 的理解和生成能力。如图 1 所示,用户上传了一张黄色花朵的图像,并输入一条复杂的语言指令「请根据该图像生成的深度图在生成一朵红色花朵,然后逐步将其制作成卡通图片。」在 Prompt Manager 帮助下,Visual ChatGPT 启动了和 VFM 相关的执行链。
其执行过程是这样的,首先是深度估计模型,用来检测图像深度信息;然后是深度 - 图像模型,用来生成具有深度信息的红花图像;最后利用基于 Stable Diffusion 的风格迁移 VFM 将该图像风格转换为卡通图像。
在上述 pipeline 中,Prompt Manager 作为 ChatGPT 的调度器,提供可视化格式的类型并记录信息转换的过程。最后,当 Visual ChatGPT 从 Prompt Manager 获得卡通提示时,它将结束执行 pipeline 并显示最终结果。
在接下来的示例中,用户输入提示:你能帮我生成一张猫的图像吗?收到指示后,Visual ChatGPT 生成一张正在看书的猫的图像。
你还可以要求 Visual ChatGPT 将图像中的猫换成狗,然后把书删除:
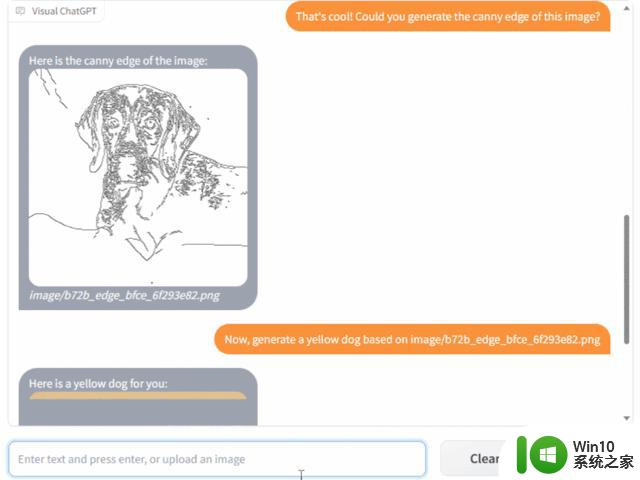
你甚至还能要求 Visual ChatGPT 生成 canny 边缘检测,然后基于此生成另一张图像:
接下来我们看看该研究是如何实现的。
方法:Visual ChatGPT
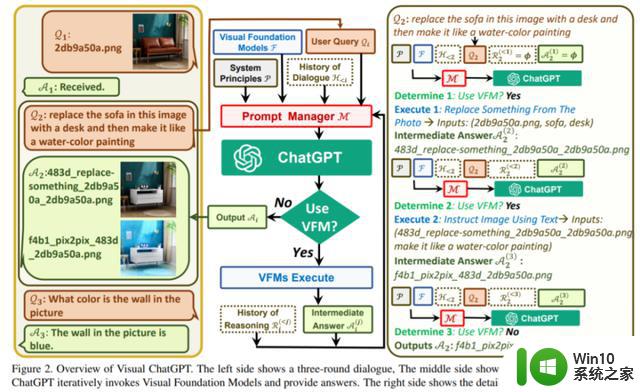
下图为 Visual ChatGPT 概览。左边进行了三轮对话,中间是 Visual ChatGPT 如何迭代调用 Visual Foundation Models 并提供答案的流程图。右侧展示了第二次 QA 的详细过程。
系统原则 prompt 管理
Visual ChatGPT 是一个集成了不同 VFM 来理解视觉信息并生成相应答案的系统。因此,Visual ChatGPT 需要定制一些系统原则,并将其转化为 ChatGPT 可以理解的 prompt。这些 prompt 有多种用途,包括:
Visual ChatGPT 本身的用途:Visual ChatGPT 旨在协助完成一系列与文本和视觉相关的任务,例如 VQA、图像生成和编辑;VFM 的可访问性:Visual ChatGPT 可以访问 VFM 列表来解决各种 VL( vision-language ) 任务。使用哪种基础模型完全由 ChatGPT 模型本身决定,因此 Visual ChatGPT 可以轻松支持新的 VFM 和 VL 任务;文件名敏感度:Visual ChatGPT 根据文件名访问图像文件,使用精确的文件名以避免歧义至关重要,因为一轮对话可能包含多个图像及其不同的更新版本,滥用文件名会导致混淆图片。因此,Visual ChatGPT 被设计为严格使用文件名,确保它检索和操作正确的图像文件;Chain-of-Thought:如上图 1 所示生成卡通图片的过程,涉及深度估计、深度到图像和风格转换的 VFM,这种看似简单的命令可能需要多个 VFM,为了通过将查询分解为子问题来解决更具挑战性的查询,Visual ChatGPT 引入了 CoT 以帮助决定、利用和调度多个 VFM;推理格式的严谨性:Visual ChatGPT 必须遵循严格的推理格式。因此,该研究使用精细的正则表达式匹配算法解析中间推理结果,并为 ChatGPT 模型构建合理的输入格式,以帮助其确定下一次执行,例如触发新的 VFM 或返回最终响应;可靠性作为一种语言模型,Visual ChatGPT 可能会伪造假图像文件名或事实,这会使系统不可靠。为了处理此类问题,该研究对 prompt 进行了设计,要求 Visual ChatGPT 忠于视觉基础模型的输出,而不是伪造图像内容或文件名。此外,多个 VFM 的协作可以提高系统可靠性,因此本文构建的 prompt 将引导 ChatGPT 优先利用 VFM,而不是根据对话历史生成结果。下表为 Visual ChatGPT 支持的 22 种基础模型:
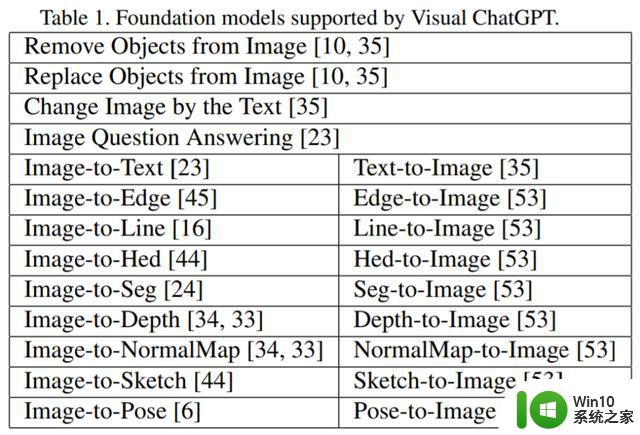
基础模型的 prompt 管理
Visual ChatGPT 配备了多个 VFM 来处理各种 VL 任务。由于这些不同的 VFM 可能有一些相似之处,例如,图像中对象的替换可以被视为生成新图像,图像到文本(I2T)任务和图像问答(VQA)任务都可以理解为根据提供的图像给出响应,区分它们至关重要。如图 3 所示,Prompt Manager 具体定义了以下几个方面来帮助 Visual ChatGPT 准确理解和处理 VL 任务:
名称:名称 prompt 为每个 VFM 提供了整体功能的抽象,例如回答关于图像的问题,它不仅有助于 Visual ChatGPT 简明扼要地理解 VFM 的用途,而且名称还是 VFM 的入口。用法:用法 prompt 描述了应该使用 VFM 的特定场景。例如,Pix2Pix 模型适用于改变图像的风格。提供此信息有助于 Visual ChatGPT 做出将哪个 VFM 用于特定任务的明智决策。输入 / 输出:输入和输出 prompt 概述了每个 VFM 所需的输入和输出格式,因为格式可能有很大差异,并且为 Visual ChatGPT 正确执行 VFM 提供明确的指导至关重要。示例(可选):示例 prompt 是可选的,但它可以帮助 Visual ChatGPT 更好地理解如何在特定的输入模板下使用特定的 VFM 以及处理更复杂的查询。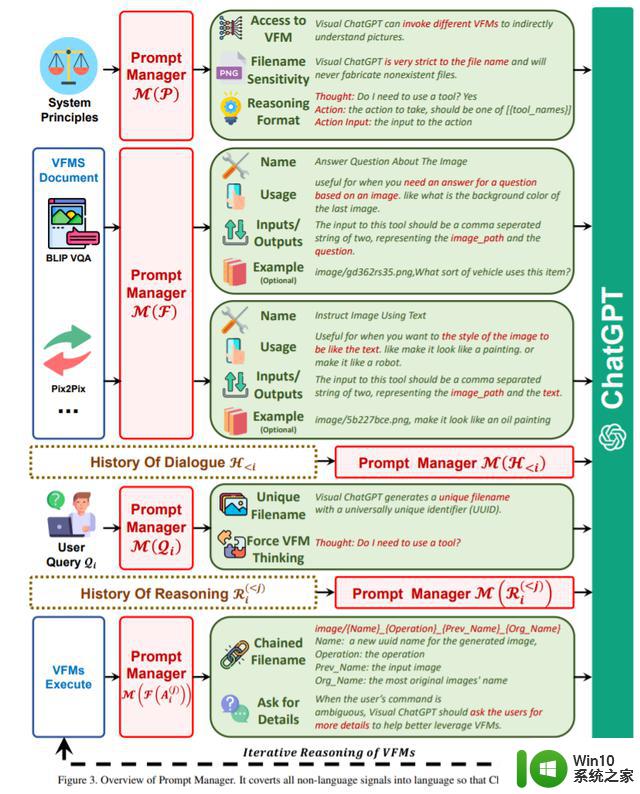
用户查询的 prompt 管理
Visual ChatGPT 支持多种用户查询,包括语言或图像,简单或复杂的查询,以及多张图片的引用。Prompt Manager 从以下两个方面处理用户查询:
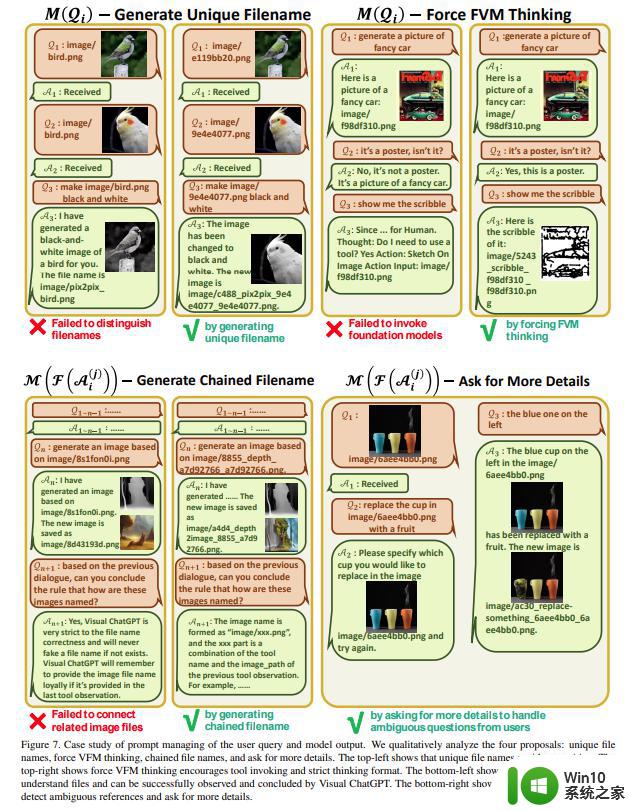
生成唯一的文件名。Visual ChatGPT 可以处理两种类型的图像相关查询:涉及新上传图像的查询和涉及引用现有图像的查询。对于新上传的图像,Visual ChatGPT 会生成一个具有通用唯一标识符 (UUID) 的唯一文件名,并添加一个前缀字符串「image」来表示相对目录,例如「image/.png」。虽然新上传的图像不会被输入 ChatGPT,但会生成一个虚假的对话历史记录,其中包含一个说明图像文件名的问题和一个表明图像已收到的答案。这个虚假的对话历史有助于以下对话。对于涉及引用现有图像的查询,Visual ChatGPT 会忽略文件名检查。这种方法已被证明是有益的,因为 ChatGPT 能够理解用户查询的模糊匹配,前提是它不会导致歧义,例如 UUID 名称。
确保正确触发 VFM。为了保证 Visual ChatGPT 的 VFM 成功触发,该研究在 后面附加了一个后缀提示,这个提示有两个目的:1)提示 Visual ChatGPT 使用基础模型,而不是仅仅依靠它的想象;2) 鼓励 Visual ChatGPT 提供由基础模型生成的特定输出,而不是通用响应。
基础模型输出的 prompt 管理

对于来自不同 VFM
的中间输出,Visual ChatGPT 将隐式汇总并将它们提供给 ChatGPT 进行后续交互,即调用其他 VFM 进行进一步操作,直到达到结束条件或将结果反馈给 ChatGPT 用户。内部步骤可以拆解为生成链式文件名、调用 VFM、询问用户更多细节以确定用户命令。
实验及结果
多轮对话完整案例
图 4 为 Visual ChatGPT 进行的 16 轮多模态对话案例。在本例中,用户同时询问文本和图像问题,Visual ChatGPT 能够以文本和图像的方式给出响应。
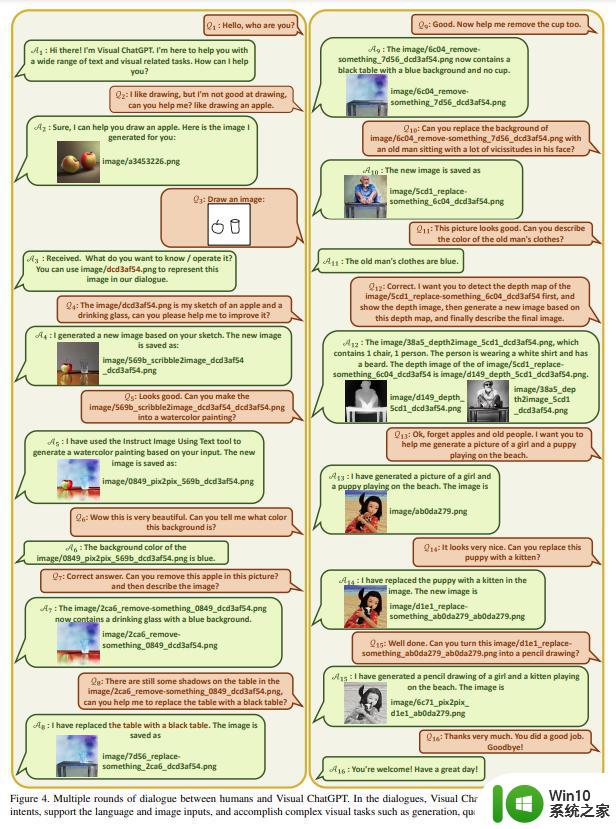
Prompt Manager 案例研究
系统原则 prompt 管理分析研究如图 5 所示:为了验证系统原则 prompt 的有效性,该研究从中删除了不同的部分来比较模型性能。结果显示每次移除都会导致不同的容量退化。

图 6 为基础模型 prompt 管理的案例分析。前面也提到 VFM 的名称非常重要,需要明确定义。当名称缺失或模糊时,Visual ChatGPT 会进行多次猜测,直到找到现有的 VFM,或遇到错误终止,如左上角所示。此外,VFM 应清楚地描述在特定的场景下所使用的模型,以避免错误的响应,右上图显示风格迁移被错误地处理成替换。还有一点需要注意的是,输入输出格式的 prompt 要准确,避免参数错误,如左下图。示例 prompt 可以帮助模型处理复杂的用法,但它是可选的,如右下图所示,虽然本文删除了示例 prompt,但 ChatGPT 还可以总结对话历史和人类意图以使用正确的 VFM。
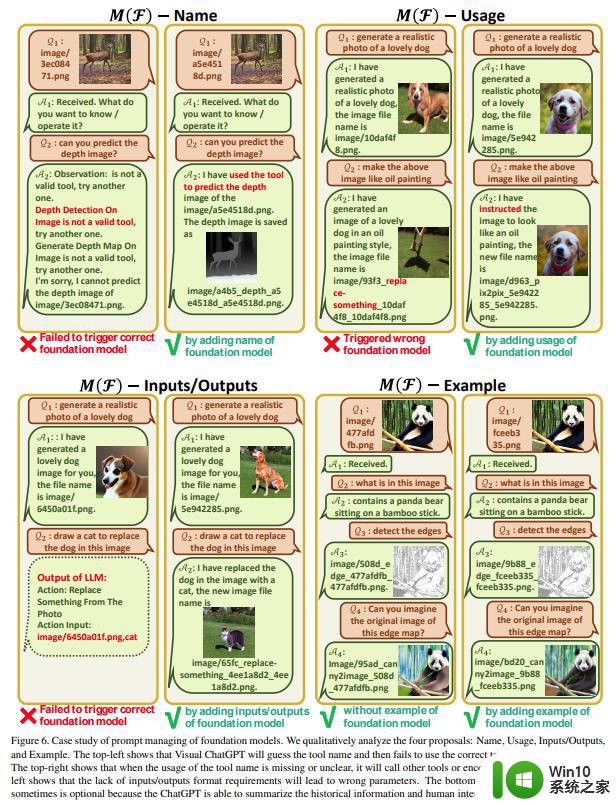
图 7 上半部分分析了用户查询 prompt 管理的案例研究,图 7 底部分析了模型输出的 prompt 管理案例。
视觉ChatGPT来了,微软发布,代码已开源相关教程
- 微软发布ChatGPT版必应!谷歌加入战局,搜索引擎迎来新时代!
- 重磅!微软宣布开源Deep Speed Chat,可将训练速度提升15倍以上,全民ChatGPT时代来了
- ChatGPT版Office来了:微软下周四举行发布会,CEO亲自上
- 微软发布新版office:集成ChatGPT,智能秘书来了!
- 定制版ChatGPT要来了?消息人士:微软今年晚些时候发布
- 微软AI聊天画图炸弹!视觉模型加持ChatGPT,Visual ChatGPT出世
- 谁泄露了推特源代码?法院要求微软旗下GitHub提供发布者信息
- 微软Bing Chat免费升级ChatGPT-4 Turbo代码解释器,带来大幅改进
- 今天,微软重新发明搜索引擎:首款ChatGPT搜索来了
- 微软宣布以公共预览形式,推出AI计算机视觉模型Florence
- 微软发布TypeScript 5.6:完善空值合并和真值检查,提升代码质量
- 微软最强开源工具箱新版发布,GitHub 收获 92.7 万星,助力开源项目生态发展
- 全球债市遭抛售,恒指或创新高,马士基业绩超预期
- 高通骁龙8至尊版发布,性能媲美桌面处理器,决胜AI时代的关键!
- 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 一个印度人救了微软,另一个毁了IBM?探讨印度人在科技行业的影响力
微软新闻推荐
- 1 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 2 英特尔AMD史诗级合作,捍卫X86生态:两大巨头联手,颠覆传统CPU格局
- 3 微信消失在桌面了,怎么找回 微信桌面快捷方式消失怎么恢复
- 4 打印机的纸怎么放进去 打印机纸盒放纸技巧
- 5 onedrive开始菜单 Win10如何设置Onedrive开启和使用
- 6 台式电脑如何连接打印机设备打印 台式电脑如何设置本地打印机
- 7 惠普笔记本win11移动硬盘怎么用 win11系统移动硬盘插入后不显示
- 8 微软称每天有超过15000条恶意QR码信息被发送到教育目标,如何有效应对?
- 9 win10系统电脑没有wifi选项 Win10无线网络不显示解决方法
- 10 win7能看见的文件夹win10看不到 win7可以访问win10但win10无法访问win7
win10系统推荐
- 1 系统之家ghost win10 64位稳定家庭版下载v2023.06
- 2 系统之家win10 64位旗舰破解版v2023.06
- 3 雨林木风ghost win10 32位家庭版正版v2023.06
- 4 雨林木风ghost win10 32位官方安装版v2023.06
- 5 电脑公司ghost win10 32位精简优化版v2023.06
- 6 电脑公司ghost win10 64位官方安全原版v2023.06
- 7 深度技术ghost win10 32位最新破解版v2023.05
- 8 电脑公司win10 64位旗舰安全版v2023.05
- 9 电脑公司ghost win10 32位免费安装版v2023.05
- 10 萝卜家园ghost windows10 32位稳定游戏版下载v2023.05
系统教程推荐
- 1 蜘蛛侠:暗影之网win10无法运行解决方法 蜘蛛侠暗影之网win10闪退解决方法
- 2 win10玩只狼:影逝二度游戏卡顿什么原因 win10玩只狼:影逝二度游戏卡顿的处理方法 win10只狼影逝二度游戏卡顿解决方法
- 3 U盘装机提示Error 15:File Not Found怎么解决 U盘装机Error 15怎么解决
- 4 《极品飞车13:变速》win10无法启动解决方法 极品飞车13变速win10闪退解决方法
- 5 window7电脑开机stop:c000021a{fata systemerror}蓝屏修复方法 Windows7电脑开机蓝屏stop c000021a错误修复方法
- 6 win10桌面图标设置没有权限访问如何处理 Win10桌面图标权限访问被拒绝怎么办
- 7 win10打不开应用商店一直转圈修复方法 win10应用商店打不开怎么办
- 8 无线网络手机能连上电脑连不上怎么办 无线网络手机连接电脑失败怎么解决
- 9 win10错误代码0xc0000098开不了机修复方法 win10系统启动错误代码0xc0000098怎么办
- 10 笔记本win10系统网络显示小地球只有飞行模式如何恢复 笔记本win10系统网络无法连接小地球图标灰色