证件照转数字人只需几秒钟,微软实现3D扩散模型高质量生成效果
转载自 微软亚洲研究院
一张2D证件照,几秒钟就能设计出3D游戏化身!
这是扩散模型在3D领域的最新成果。例如,只需一张法国雕塑家罗丹的旧照,就能分分钟把他“变”进游戏中:

△RODIN模型基于罗丹旧照生成的3D形象
甚至只需要一句话就能修改装扮和形象。告诉AI生成罗丹“穿着红色毛衣戴着眼镜的造型”:

不喜欢大背头?那就换成“扎着辫子的造型”:

再试试换个发色?这是“棕色头发的时尚潮人造型”,连胡子颜色都搞定了:

(AI眼中的“时尚潮人”,确实有点潮过头了)
上面这个最新的3D生成扩散模型“罗丹”RODIN(Roll-out Diffusion Network),来自微软亚洲研究院。
RODIN也是首个利用生成扩散模型在3D训练数据上自动生成3D数字化身(Avatar)的模型,论文目前已被CVPR 2023接收。
一起来看看。
直接用3D数据训练扩散模型这个3D生成扩散模型“罗丹”RODIN的名字,灵感来源于法国雕塑艺术家奥古斯特·罗丹(Auguste Rodin)。
此前2D生成3D图像模型,通常用2D数据训练生成对抗网络(GAN)或变分自编码器(VAE)得到,但结果往往不尽人意。
研究人员分析,造成这种现象的原因在于这些方法存在一个基础的欠定(ill posed)问题。即由于单视角图片存在几何二义性,仅仅通过大量的2D数据,很难学到高质量3D化身的合理分布,导致生成效果不好。
因此,他们这次尝试直接用3D数据来训练扩散模型,主要解决了三个难题:
首先,如何用扩散模型生成3D模型多视角图。此前扩散模型在3D数据上没有可参考实践方法和可遵循前例。其次,高质量和大规模3D图像数据集很难获取,且存在隐私版权风险,但网络公开3D图像无法保证多视图一致性。最后, 2D扩散模型直接拓展成3D生成,所需的内存、存储与计算开销极大。为了解决这三个难题,研究人员提出了“AI雕塑家”RODIN扩散模型,超越了现有模型的SOTA水平。
RODIN模型采用神经辐射场(NeRF)方法,借鉴英伟达的EG3D工作,将3D空间紧凑地表达为空间三个互相垂直的特征平面(Triplane),并将这些图展开至单个2D特征平面中,再执行3D感知扩散。
具体而言,就是将3D空间在横、纵、垂三个正交平面视图上以二维特征展开,这样不仅可以让RODIN模型使用高效的2D架构进行3D感知扩散,而且将3D图像降维成2D图像也大幅降低了计算复杂度和计算成本。
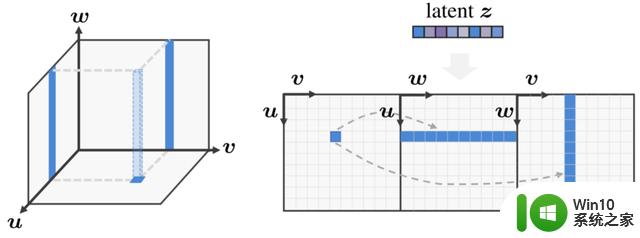
△3D感知卷积高效处理3D特征
上图左边,用三平面(triplane)表达3D空间,此时底部特征平面的特征点对应于另外两个特征平面的两条线;上图右边,则引入3D感知卷积处理展开的2D特征平面,同时考虑到三个平面的三维固有对应关系。
具体而言,实现3D图像的生成需要三个关键要素:
其一,3D感知卷积,确保降维后的三个平面的内在关联。
传统2D扩散中使用的2D卷积神经网络(CNN),并不能很好地处理Triplane特征图。
3D感知卷积并不是简单生成三个2D特征平面,而是在处理这样的3D表达时,考虑了其固有的三维特性,即三个视图平面中其中一个视图的2D特征本质上是3D空间中一条直线的投影,因此与其他两个平面中对应的直线投影特征存在关联性。
为了实现跨平面通信,研究员们在卷积中考虑了这样的3D相关性,因此高效地用2D的方式合成3D细节。
其二,隐空间协奏三平面3D表达生成。
研究员们通过隐向量来协调特征生成,使其在整个三维空间中具有全局一致性,从而获得更高质量的化身并实现语义编辑。
同时,还通过使用训练数据集中的图像训练额外的图像编码器,该编码器可提取语义隐向量作为扩散模型的条件输入。
这样,整体的生成网络可视为自动编码器,用扩散模型作为解码隐空间向量。对于语义可编辑性,研究员们采用了一个冻结的CLIP图像编码器,与文本提示共享隐空间。
其三,层级式合成,生成高保真立体细节。
研究员们利用扩散模型,先生成了一个低分辨率的三视图平面(64×64),然后再通过扩散上采样生成高分辨率的三平面(256×256)。
这样,基础扩散模型集中于整体3D结构生成,而后续上采样模型专注于细节生成。
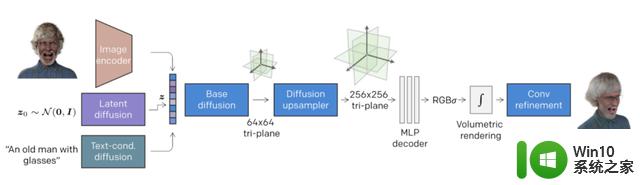
△RODIN模型概述
基于Blender生成大量随机数据在训练数据集上,研究员们借助开源的三维渲染软件Blender。通过随机组合画师手动创建的虚拟3D人物图像,再加上从大量头发、衣服、表情和配饰中随机采样,进而创建了10万个合成个体,同时为每个个体渲染出了300个分辨率为256*256的多视图图像。
在文本到3D头像的生成上,研究员们采用了LAION-400M数据集的人像子集,训练从输入模态到3D扩散模型隐空间的映射,最终让RODIN模型只使用一张2D图像或一句文字描述,就能创建出逼真的3D头像。

△给定一张照片生成虚拟形象
不仅能一句话改变形象,如“留卷发和大胡子穿着黑色皮夹克的男性”:

甚至连性别都能随意更换,“红色衣着非洲发型的女性”:(手动狗头)

研究人员也给出了一个应用Demo示范,创建自己的形象只需要几个按钮:
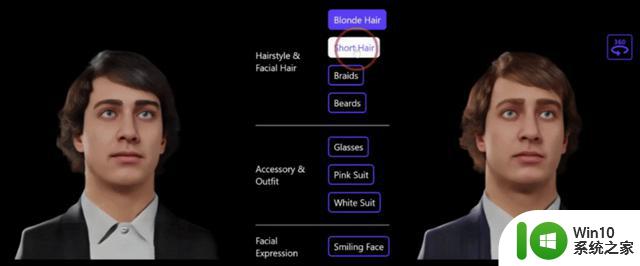
△利用文字做3D肖像编辑
更多效果可以戳项目地址查看~

△更多随机生成的虚拟形象
做出了RODIN后,团队接下来的计划是?
据微软亚洲研究院作者们表示,目前RODIN的作品还主要停留在3D半身人像上,这也与它主要采用人脸数据训练有关,但3D图像生成需求不仅局限于人脸上。
下一步,团队将会考虑尝试用RODIN模型创建更多3D场景,包括花草树木、建筑、汽车家居等,实现“一个模型生成3D万物”的终极目标。
论文地址:
https://arxiv.org/abs/2212.06135
项目页面:
https://3d-avatar-diffusion.microsoft.com
— 完 —
量子位 QbitAI · 头条号签约
关注我们,第一时间获知前沿科技动态
证件照转数字人只需几秒钟,微软实现3D扩散模型高质量生成效果相关教程
- 微软发布VASA-1:单张照片生成超现实真人视频,性能领先SOTA
- 微软Win11 22H2配置更新:新增中文实时字幕,时钟可显示秒数
- 元宇宙新鲜事|微软推出全能型人工智能模型Kosmos-1 智度股份:元宇宙业务有实质性营收
- 微软必应再强化!接入OpenAI DALL·E模型,文字生成图像
- 照片如何变成一寸蓝底 一寸照片如何实现蓝底效果
- 微软数字化转型评估服务,为企业上云转型悬丝诊脉
- 几秒钟做成PPT、Excel!微软重磅发布:GPT-4植入Office全家桶!打工人的工作方式被颠覆?
- 微软Win11新版照片功能体验:快速生成优质海报邀请函
- 微软第一财季营收高于预期,实现了令人瞩目的表现
- 微软iOS版PowerPoint升级:模板数量从24个扩充到71个
- 微软大模型WaveCoder!2万个实例数据集,提升LLM泛化能力
- 手机拍的照片怎么弄成证件照 如何将手机照片转换为证件照
- 全球债市遭抛售,恒指或创新高,马士基业绩超预期
- 高通骁龙8至尊版发布,性能媲美桌面处理器,决胜AI时代的关键!
- 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 一个印度人救了微软,另一个毁了IBM?探讨印度人在科技行业的影响力
微软新闻推荐
- 1 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 2 英特尔AMD史诗级合作,捍卫X86生态:两大巨头联手,颠覆传统CPU格局
- 3 微信消失在桌面了,怎么找回 微信桌面快捷方式消失怎么恢复
- 4 打印机的纸怎么放进去 打印机纸盒放纸技巧
- 5 onedrive开始菜单 Win10如何设置Onedrive开启和使用
- 6 台式电脑如何连接打印机设备打印 台式电脑如何设置本地打印机
- 7 惠普笔记本win11移动硬盘怎么用 win11系统移动硬盘插入后不显示
- 8 微软称每天有超过15000条恶意QR码信息被发送到教育目标,如何有效应对?
- 9 win10系统电脑没有wifi选项 Win10无线网络不显示解决方法
- 10 win7能看见的文件夹win10看不到 win7可以访问win10但win10无法访问win7
win10系统推荐
- 1 系统之家ghost win10 64位稳定家庭版下载v2023.06
- 2 系统之家win10 64位旗舰破解版v2023.06
- 3 雨林木风ghost win10 32位家庭版正版v2023.06
- 4 雨林木风ghost win10 32位官方安装版v2023.06
- 5 电脑公司ghost win10 32位精简优化版v2023.06
- 6 电脑公司ghost win10 64位官方安全原版v2023.06
- 7 深度技术ghost win10 32位最新破解版v2023.05
- 8 电脑公司win10 64位旗舰安全版v2023.05
- 9 电脑公司ghost win10 32位免费安装版v2023.05
- 10 萝卜家园ghost windows10 32位稳定游戏版下载v2023.05
系统教程推荐
- 1 蜘蛛侠:暗影之网win10无法运行解决方法 蜘蛛侠暗影之网win10闪退解决方法
- 2 win10玩只狼:影逝二度游戏卡顿什么原因 win10玩只狼:影逝二度游戏卡顿的处理方法 win10只狼影逝二度游戏卡顿解决方法
- 3 U盘装机提示Error 15:File Not Found怎么解决 U盘装机Error 15怎么解决
- 4 《极品飞车13:变速》win10无法启动解决方法 极品飞车13变速win10闪退解决方法
- 5 window7电脑开机stop:c000021a{fata systemerror}蓝屏修复方法 Windows7电脑开机蓝屏stop c000021a错误修复方法
- 6 win10桌面图标设置没有权限访问如何处理 Win10桌面图标权限访问被拒绝怎么办
- 7 win10打不开应用商店一直转圈修复方法 win10应用商店打不开怎么办
- 8 无线网络手机能连上电脑连不上怎么办 无线网络手机连接电脑失败怎么解决
- 9 win10错误代码0xc0000098开不了机修复方法 win10系统启动错误代码0xc0000098怎么办
- 10 笔记本win10系统网络显示小地球只有飞行模式如何恢复 笔记本win10系统网络无法连接小地球图标灰色