微软发布VASA-1:单张照片生成超现实真人视频,性能领先SOTA
现在 Microsoft Research 推出了VASA-1项目,同样是单张人像照片+语音音频=超现实的说话脸视频,但是性能SOTA!
GPT-3.5研究测试:
https://hujiaoai.cn
GPT-4研究测试:
https://higpt4.cn
Claude-3研究测试(全面吊打GPT-4):
https://hiclaude3.com
VASA-1 可实现精确的唇声同步,逼真的面部行为,自然的头部运动,并支持实时生成!

据作者报道,该 VASA-1 不仅能够产生与音频同步的嘴唇动作,而且还能够捕捉到大量的面部细微差别和自然的头部动作,从而有助于感知真实性和人物状态。
,时长00:15
可以看到表情非常到位,特别是那灵活的小眼神!
相比之前的高启强普法视频,眼神、眉毛的动作显然要自然很多。
,时长00:17
更好的可控性VASA-1 的一个显著的特性是它可以接受可选信号作为条件,如主眼睛注视方向和头部距离,以及情绪偏移。这不仅增强了可玩性,重要的是动画效果更加自然!
,时长00:12
▲不同主注视方向(前、左、右、上)下的生成结果
,时长00:12
▲不同头距尺度下的生成结果
,时长00:11
▲不同情绪(分别为中性、快乐、愤怒、惊讶)下的生成结果
非常优秀的分布外泛化能力对于分布外的照片,比如油画、动漫中的人物,也一样可以让他或自然或鬼畜的说话!
,时长00:22
,时长01:17
,时长00:15
实时生成高质量内容不仅生成的效果非常逼真,VASA-1更是支持在离线批处理模式下以45fps的速度生成512x512大小的视频帧,在在线流媒体模式下可以支持高达40fps的视频帧,前延迟仅为170ms!
,时长00:34
官方的展示demo中丝滑的生成过程以及丰富的可编辑选项都能看出这项工作的成熟度,真是把吃瓜群众都给看急眼了,究竟啥时候才能玩啊。
什么是VASA-1区别于以往的方法,VASA-1不直接生成视频帧,而是根据声音和其他信号在潜在空间中生成整体面部动态和头部运动。
VASA-1 的面部解码器将这些动作潜在编码生成视频帧,同时也将从输入图像中提取的外观和身份特征作为输入。
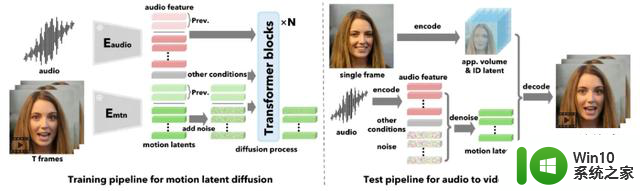
在论文中,作者还研究了音频和头部姿态之间的同步性测量问题,并提出了一种新的度量方法,称为“Contrastive Audio and Pose Pretraining”(CAPP)分数。
据作者介绍,这个方法受到了CLIP模型的启发,它通过联合训练一个姿态序列编码器和一个音频序列编码器来工作,其目标则是预测输入的姿态序列和音频是否配对。其中的音频编码器是基于一个预训练的Wav2Vec2网络初始化的,而姿态编码器是一个随机初始化的6层 transformer。
该 CAPP模型在大约2000小时的真实生活音频和姿态序列上进行了训练,并且展示了强大的能力来评估音频输入和生成的姿态之间的同步程度。
或者正是通过这种音频和头部姿态的对齐预训练才使得 VASA-1具有这么逼真的生成效果吧!
怎么还不开源?微软表示,在还不能避免技术滥用的情况下,他们不打算发布在线演示、API、产品、其他实现细节或任何相关产品,直到确定该技术将被负责任地使用。或者这也是阿里的 EMO 迟迟没有更新 github 的原因吧?那为啥腾讯就发布了捏?

微软发布VASA-1:单张照片生成超现实真人视频,性能领先SOTA相关教程
- 一周网事丨2023年领先科技成果及实践案例征集宣介会举办 微软将对AI生成内容添加水印打击深度伪造
- 一键生成PPT等!微软深夜重磅发布,打工人笑完就哭了
- 微软狂买AMD的AI芯片,引领人工智能技术发展
- 微软突放大招,新Bing人人可用,支持图片生成和插件开放,频繁更新下日活已超1亿
- 证件照转数字人只需几秒钟,微软实现3D扩散模型高质量生成效果
- Intel CEO亲口承认:NVIDIA确实是AI的王者!遥遥领先的真实认可
- 微软Win11新版照片功能体验:快速生成优质海报邀请函
- 微软最新研究表明,人工智能领域的发展速度正在超出人类的控制
- 微软发布AI超级应用,牛得不像微软
- 全球科技早参|李飞飞团队携手谷歌发布视频生成模型W.A.L.T
- Quisitive与微软合作开发生成式AI工具并用于医疗保健等领域
- 微软发布Windows Copilot,打造Win11人工智能“个人助理”
- 全球债市遭抛售,恒指或创新高,马士基业绩超预期
- 高通骁龙8至尊版发布,性能媲美桌面处理器,决胜AI时代的关键!
- 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 一个印度人救了微软,另一个毁了IBM?探讨印度人在科技行业的影响力
微软新闻推荐
- 1 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 2 英特尔AMD史诗级合作,捍卫X86生态:两大巨头联手,颠覆传统CPU格局
- 3 微信消失在桌面了,怎么找回 微信桌面快捷方式消失怎么恢复
- 4 打印机的纸怎么放进去 打印机纸盒放纸技巧
- 5 onedrive开始菜单 Win10如何设置Onedrive开启和使用
- 6 台式电脑如何连接打印机设备打印 台式电脑如何设置本地打印机
- 7 惠普笔记本win11移动硬盘怎么用 win11系统移动硬盘插入后不显示
- 8 微软称每天有超过15000条恶意QR码信息被发送到教育目标,如何有效应对?
- 9 win10系统电脑没有wifi选项 Win10无线网络不显示解决方法
- 10 win7能看见的文件夹win10看不到 win7可以访问win10但win10无法访问win7
win10系统推荐
- 1 系统之家ghost win10 64位稳定家庭版下载v2023.06
- 2 系统之家win10 64位旗舰破解版v2023.06
- 3 雨林木风ghost win10 32位家庭版正版v2023.06
- 4 雨林木风ghost win10 32位官方安装版v2023.06
- 5 电脑公司ghost win10 32位精简优化版v2023.06
- 6 电脑公司ghost win10 64位官方安全原版v2023.06
- 7 深度技术ghost win10 32位最新破解版v2023.05
- 8 电脑公司win10 64位旗舰安全版v2023.05
- 9 电脑公司ghost win10 32位免费安装版v2023.05
- 10 萝卜家园ghost windows10 32位稳定游戏版下载v2023.05
系统教程推荐
- 1 蜘蛛侠:暗影之网win10无法运行解决方法 蜘蛛侠暗影之网win10闪退解决方法
- 2 win10玩只狼:影逝二度游戏卡顿什么原因 win10玩只狼:影逝二度游戏卡顿的处理方法 win10只狼影逝二度游戏卡顿解决方法
- 3 U盘装机提示Error 15:File Not Found怎么解决 U盘装机Error 15怎么解决
- 4 《极品飞车13:变速》win10无法启动解决方法 极品飞车13变速win10闪退解决方法
- 5 window7电脑开机stop:c000021a{fata systemerror}蓝屏修复方法 Windows7电脑开机蓝屏stop c000021a错误修复方法
- 6 win10桌面图标设置没有权限访问如何处理 Win10桌面图标权限访问被拒绝怎么办
- 7 win10打不开应用商店一直转圈修复方法 win10应用商店打不开怎么办
- 8 无线网络手机能连上电脑连不上怎么办 无线网络手机连接电脑失败怎么解决
- 9 win10错误代码0xc0000098开不了机修复方法 win10系统启动错误代码0xc0000098怎么办
- 10 笔记本win10系统网络显示小地球只有飞行模式如何恢复 笔记本win10系统网络无法连接小地球图标灰色