ChatGPT真实参数只有200亿,网友惊呼:微软将开源?
在阅读此文之前,麻烦您点击一下“关注”,既方便您进行讨论和分享,又能给您带来不一样的参与感,感谢您的支持。
标题:技术革新的新潮:深入探究微软新研究的震撼与启示导语:近日,一个关于人工智能的新突破引发了行业的热烈讨论。一个微软研究团队发布的论文不仅公开了一个意外的秘密,而且介绍了一种创新的编码模型。这不仅仅是关于参数的数量,更是关于技术如何以更少的资源达到前所未有的效果。
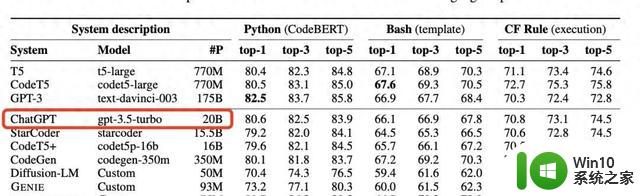
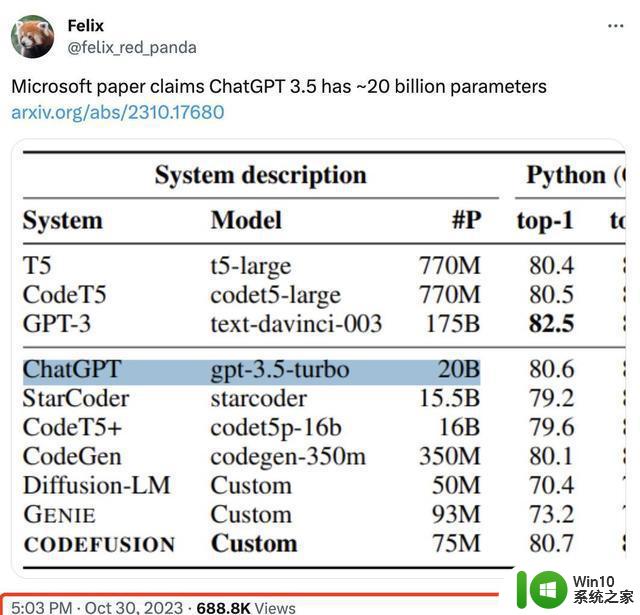
正文:整个人工智能社区最近被一个发现搅动了,讨论的焦点是一个看似平常的统计图表。微软的一篇新论文意外透露了一个信息:一个业界领先的大模型——被广泛应用的ChatGPT——可能只拥有200亿的参数量,远低于人们预期的规模。

这一数字一经公布,迅速在全球范围内引起了轩然大波。网络上的热议中,有些人怀疑是否是一个拼写错误。这一怀疑背后,是对OpenAI以往对大模型保密态度的理解,也反映出对未来可能开源的期待。

而这并非个例,在GitHub Copilot的API中,也有人发现了暗示着GPT-4更新的线索。这一切加起来,似乎在向我们预示着某种新的变革即将到来。
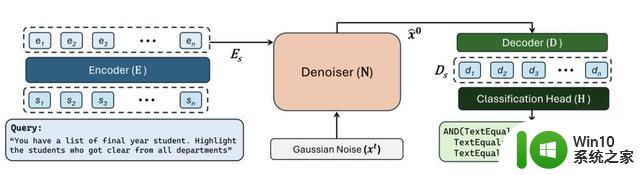
那么,这篇引发广泛关注的论文具体包含了哪些内容呢?论文不仅泄露了“秘密”,更重要的是,它首次介绍了使用扩散模型进行代码生成的新方法。这种方法对代码生成领域来说,是一种革命性的尝试。

微软的研究员们设计了一个名为CODEFUSION的编码-解码架构。它的工作方式类似于一种编译过程,将自然语言的输入转化为连续的表示,再通过Diffusion模型进行迭代去噪处理。这一创新架构的目标是提高代码生成的准确性,并在代码的多样性与质量之间找到一个更好的平衡。
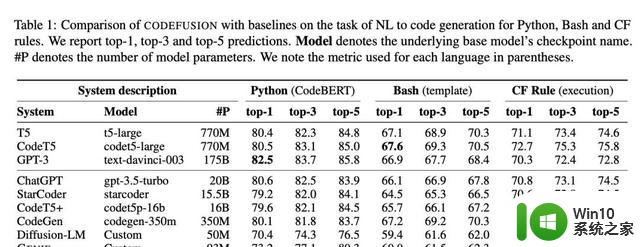
在三个不同的编程任务上对CODEFUSION进行了测试,包括Python、Bash和Excel的条件格式化。结果令人瞩目,即使是7500万参数的CODEFUSION,其表现也能媲美200亿参数的GPT-3.5-turbo,并在代码的多样性上有了显著提高。

相比于传统的自回归模型和纯文本生成模型,CODEFUSION在生成语法正确的代码方面表现得更为出色。它在保持精确度的同样地,提供了更多样化的编码选择。尤其是在生成前三名和前五名准确代码的能力上,CODEFUSION超过了现有的先进系统。
这一发现原本只是对性能的常规比较,却在技术社区引起了巨大的反响。有人甚至提出了阴谋论,认为这可能是OpenAI有意为之的开源“前菜”。考虑到已经有不少模型追赶上来,以及早在今年5月就有报道称OpenAI准备开源新的语言模型,这一猜测并非完全没有根据。
更有趣的是,早在今年2月份的一篇福布斯报道中,就已经提到了ChatGPT只有200亿参数的说法。尽管如此,那时这一消息并未引起广泛关注,直到如今这一波讨论的兴起。
结语:这篇重新构建的文章不仅提供了技术的新视角,还激起了对未来的深思。微软的新研究不仅仅揭示了一个关于模型参数量的惊人事实,它更是一种对现有AI开发方法的挑战和创新。这标志着我们正在步入一个新的时代,在这个时代中,技术的效率和创新将比单纯的规模更为重要。随着行业对这些新发现的深入探讨,我们可以预见,这将对未来的技术发展和开源文化产生深远的影响。


标题:技术革新的新潮:微软研究的震撼与启示导语:近日,一篇由微软研究团队发布的论文引发了人工智能领域的广泛讨论。不仅揭示了一个令人意外的模型参数量秘密,还带来了一种革命性的编码模型。这一发现不仅关乎规模,更涉及技术如何以更少的资源实现卓越的效果。
正文:整个人工智能社区最近被一项发现搅动,一个看似普通的统计图表成为了焦点。微软的这篇新论文揭示了一个惊人的信息:业界广泛应用的ChatGPT可能只包含着200亿参数,这一数字远低于人们的预期。这一揭示在全球范围内引发了广泛的争议,有些人甚至怀疑这是否是拼写错误,反映了对OpenAI以往对大模型保密的不解与期待未来的开源。
此外,GitHub Copilot的API中也暗示着GPT-4的更新,这一线索进一步加深了行业对未来的期望,似乎在暗示着某种新的技术变革即将到来。这一连串的迹象似乎在为一个新的技术时代的到来铺平道路。
那么,这篇备受关注的论文到底包含了哪些内容呢?该论文不仅透露了参数规模的“秘密”,更为重要的是,首次介绍了使用扩散模型进行代码生成的全新方法。这种方法在代码生成领域具有革命性意义。
微软的研究员们设计了一个名为CODEFUSION的编码-解码架构,类似于编译过程,将自然语言输入转化为连续的表示,然后通过Diffusion模型进行迭代去噪处理。该架构的目标是提高代码生成的准确性,找到代码多样性与质量之间的更好平衡。
CODEFUSION在三个不同的编程任务上进行了测试,包括Python、Bash和Excel的条件格式化。结果令人瞩目,即使是7500万参数的CODEFUSION,其表现也能媲美200亿参数的GPT-3.5-turbo,且在代码多样性方面有了显著提高。相较于传统的自回归模型和纯文本生成模型,CODEFUSION在生成语法正确的代码方面表现更出色。提供更多样化的编码选择,特别在生成前三名和前五名准确代码的能力上超越了现有的先进系统。
这一发现原本只是性能比较的一部分,但在技术社区中引发了巨大的反响。有人提出了开源“前菜”的阴谋论,考虑到不少模型已经在迎头赶上,以及OpenAI计划在未来开源新的语言模型,这一猜测也不无道理。值得注意的是,早在今年2月的一篇福布斯报道中就提到了ChatGPT只有200亿参数的说法,但那时没有引起广泛关注,直到近期的讨论才愈发热烈。
结语:这篇论文提供了技术的新视角,同时挑战和创新了现有的AI开发方法。它不仅揭示了有关模型参数量的惊人事实,更预示着我们正迈入一个新的技术时代,其中技术的效率和创新将比单纯的规模更为重要。随着行业对这些新发现的深入探讨,我们可以预见,这将对未来的技术发展和开源文化产生深远的影响。这一发现不仅令人震撼,也为技术领域的未来开启了新的篇章。
ChatGPT真实参数只有200亿,网友惊呼:微软将开源?相关教程
- 微软宣布明天举行惊喜活动,预计将有Bing ChatGPT出现
- 贴微软ChatGPT概念,亿联网络声称有人工智能技术储备
- 微软要投资近900亿搞ChatGPT,真的能如比盖茨说的改变世界吗?
- 微软多模态ChatGPT来了?16亿参数搞定看图答题、智商测验等任务
- 微软2023大会全解析,除ChatGPT加持,Windows还有哪些惊喜?
- 揭秘ChatGPT背后天价超算!上万颗英伟达A100,烧光微软数亿美元
- 科技巨头血拼:微软豪掷数亿造ChatGPT超算,谷歌加急测试Big Bard
- 8000亿欧元能源代价,千亿美元GDP下滑;微软已为ChatGPT版必应接洽广告商
- 实现自然的人机交互 微软将ChatGPT应用于机器人
- 微软将参加11月3日-5日举行的Ubuntu峰会,展示其对Linux开源社区的重要参与
- 为什么微软净利超200亿美元后股价跳水近4%?
- 又是ChatGPT!微软这一举动正在将科幻带入现实
- 全球债市遭抛售,恒指或创新高,马士基业绩超预期
- 高通骁龙8至尊版发布,性能媲美桌面处理器,决胜AI时代的关键!
- 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 一个印度人救了微软,另一个毁了IBM?探讨印度人在科技行业的影响力
微软新闻推荐
- 1 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 2 英特尔AMD史诗级合作,捍卫X86生态:两大巨头联手,颠覆传统CPU格局
- 3 微信消失在桌面了,怎么找回 微信桌面快捷方式消失怎么恢复
- 4 打印机的纸怎么放进去 打印机纸盒放纸技巧
- 5 onedrive开始菜单 Win10如何设置Onedrive开启和使用
- 6 台式电脑如何连接打印机设备打印 台式电脑如何设置本地打印机
- 7 惠普笔记本win11移动硬盘怎么用 win11系统移动硬盘插入后不显示
- 8 微软称每天有超过15000条恶意QR码信息被发送到教育目标,如何有效应对?
- 9 win10系统电脑没有wifi选项 Win10无线网络不显示解决方法
- 10 win7能看见的文件夹win10看不到 win7可以访问win10但win10无法访问win7
win10系统推荐
- 1 系统之家ghost win10 64位稳定家庭版下载v2023.06
- 2 系统之家win10 64位旗舰破解版v2023.06
- 3 雨林木风ghost win10 32位家庭版正版v2023.06
- 4 雨林木风ghost win10 32位官方安装版v2023.06
- 5 电脑公司ghost win10 32位精简优化版v2023.06
- 6 电脑公司ghost win10 64位官方安全原版v2023.06
- 7 深度技术ghost win10 32位最新破解版v2023.05
- 8 电脑公司win10 64位旗舰安全版v2023.05
- 9 电脑公司ghost win10 32位免费安装版v2023.05
- 10 萝卜家园ghost windows10 32位稳定游戏版下载v2023.05
系统教程推荐
- 1 蜘蛛侠:暗影之网win10无法运行解决方法 蜘蛛侠暗影之网win10闪退解决方法
- 2 win10玩只狼:影逝二度游戏卡顿什么原因 win10玩只狼:影逝二度游戏卡顿的处理方法 win10只狼影逝二度游戏卡顿解决方法
- 3 U盘装机提示Error 15:File Not Found怎么解决 U盘装机Error 15怎么解决
- 4 《极品飞车13:变速》win10无法启动解决方法 极品飞车13变速win10闪退解决方法
- 5 window7电脑开机stop:c000021a{fata systemerror}蓝屏修复方法 Windows7电脑开机蓝屏stop c000021a错误修复方法
- 6 win10桌面图标设置没有权限访问如何处理 Win10桌面图标权限访问被拒绝怎么办
- 7 win10打不开应用商店一直转圈修复方法 win10应用商店打不开怎么办
- 8 无线网络手机能连上电脑连不上怎么办 无线网络手机连接电脑失败怎么解决
- 9 win10错误代码0xc0000098开不了机修复方法 win10系统启动错误代码0xc0000098怎么办
- 10 笔记本win10系统网络显示小地球只有飞行模式如何恢复 笔记本win10系统网络无法连接小地球图标灰色