AMD最强AI芯片挑战NVIDIA:单芯片可处理大模型,晶体管数量达1530亿!

6月14日消息,处理器大厂AMD在美国旧金山举行的 “数据中心与人工智能技术发布会”,正式发布了新一代的面向AI及HPC领域的GPU产品——Instinct MI 300系列。
其中MI300X则是目前全球最强的生成式AI加速器,集成了高达1530亿个晶体管。并支持高达 192 GB 的 HBM3内存,多项规格超越了英伟达(NVIDIA)最新发布的H100芯片,为当下受困于英伟达垄断且供应紧张的生成式AI芯片市场带来了新的选择。

据悉,Meta、亚马逊等大厂也作为其客户代表出席了本次活动。业界也纷纷看好MI 300系列芯片有望挑战英伟达目前在AI市场的霸主地位。
与此同时,AMD还推出了面向数据中心的第四代的Epyc产品。
MI300A:最高1530亿个晶体管,集成13 个5nm的小芯片
AMD CEO苏姿丰表示,生成式AI和大语言模型(LLM)需要电脑的算力和内存大幅提高。预计今年,数据中心AI加速器的市场将达到300亿美元左右,到2027年将超过1500亿美元,复合年增长率超过50%。这意味着未来四年的CAGR将会超过50%。

正是基于AI加速器市场的庞大需求和高速增长趋势,AMD顺势推出了 Instinct MI300系列,此次发布的包括MI300A和MI300X。
从设计上来看,作为将大型片采用Chiplet设计的先行者。AMD MI300A同样也是采用了Chiplet设计,其内部拥有多达13个小芯片,均基于台积电5nm或6nm制程工艺(CPU/GPU计算核心为5nm,HBM内存和I/O等为6nm),其中许多是 3D 堆叠的,以便创建一个面积可控的单芯片封装,总共集成1460 亿个晶体管。

具体来说,MI300A与上一代的MI250X一脉相承,采用新一代的CDNA 3 GPU架构,并集成了24个Zen 4 CPU内核,配置了128GB的HBM3内存。从芯片的照片上我们可以看到,MI300A的计算核心被 8 个HBM3内存包围,单个HBM3的带宽为6.3GB/s,八个16GB堆栈形成128GB统一内存,带宽高达5.2 TB/s。

据外媒Seminalysis报道称,MI300的所有变体都以相同的基础构建块(称为AID)、有源内插器管芯开始。这个名为Elk Range的Chiplet小芯片,尺寸约为370mm2,采用台积电的N6工艺技术制造。该芯片包含2个HBM内存控制器、64MB内存附加末级(MALL)缓存、3个最新一代视频解码引擎、36个xGMI/PCIe/CXL通道,以及AMD的片上网络(NOC)。在4个小芯片的配置中,拥有256MB的MALL缓存,达到了英伟达H100的50MB的MALL缓存的5倍。
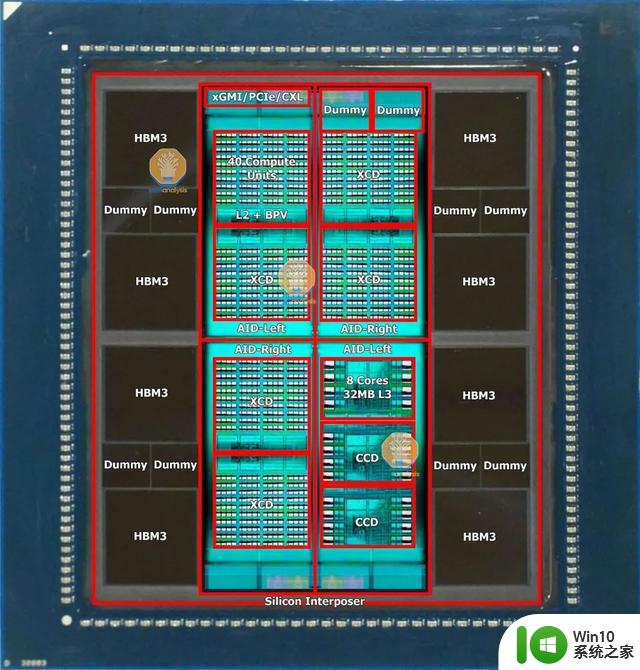
AID最重要的部分是它在CPU和GPU计算方面的模块化。AMD和台积电使用混合键合(hybrid bonding技术)将AID连接到其他小芯片。这种连接,通过铜TSV允许AMD混合和匹配CPU与GPU的最佳比例。
这四个AID以超过4.3 TB/s的平分带宽相互通信,通过类似AMD的Navi31游戏显卡GPU当中的小芯片互连上的超短距离(USR)物理层实现,尽管这次同时具有水平和垂直链路以及对称的读/写带宽。方形拓扑还意味着对角连接需要2 hops,而相邻AID需要1 hop。
这些AID中的2或4个,根据MI300变体具有不同的计算能力,被分组在CoWoS硅中介层的顶部。AID有两种不同的tape outs输出,它们与英特尔的Sapphire Rapids非常相似。
具体到GPU核心方面,其计算小芯片被称为XCD,代号为Banff,基于台积电N5工艺,面积约为115平方毫米,总共包含40个计算单元,尽管只启用了38个CU。该架构是从AMD的MI250X演变而来的,在GitHub上,AMD称其为GFX940,但公开称其为CDNA3。它针对计算进行了优化,尽管是一个“GPU”,但无法真正进行图形处理,同样英伟达的H100也是如此,它们的大部分GPC都无法进行图形处理。
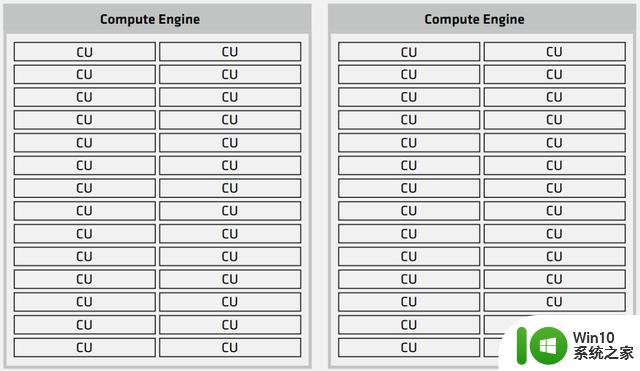
每个AID总共可以有2个Banff管芯,总共有76个CU。MI300A的最大XCD/GPU配置将提供304个CU。相比之下,AMD的MI250X拥有220个CU。
MI300A的另一个模块化计算方面是CPU端。AMD部分重复使用他们的Zen 4 CCD芯片设计,尽管有一些修改。他们改变了一些金属层掩模,为SoIC和AID创建了焊盘,这就需要重新设计一些金属掩模来进行新的tape out。这个修改的Zen 4 CCD,GD300 Durango禁用了GMI3 PHY。到AID的带宽明显高于GMI3。该CCD采用台积电的5nm工艺技术,保持了与台式机和服务器上的Zen 4 CCD相同的约70.4平方毫米的芯片尺寸。
每个AID可以有3个Zen 4小芯片,总共24个核心。MI300A的最大CCD/CPU配置可以提供多达96个内核。
Seminalysis称,AMD的MI300A是世界上最令人难以置信的先进封装形式。总共100多块硅片粘在一起,所有这些都基于使用台积电CoWoS-s技术的破纪录的3.5倍掩模版硅插入器的顶部。这种硅的范围从HBM存储器层到用于计算的有源中介层,再到用于结构支撑的空白硅。这个巨大的内插器的尺寸几乎是英伟达H100的两倍。这也使得MI300的封装工艺流程非常复杂。
苏姿丰表示,MI300A将会将提供比前一代的MI250X(理论算力47.87TFLOPS,总功耗为500W)大约快 8 倍的 AI 性能,同时每瓦性能也将提高5倍。
Seminalysis也表示,“MI300A是迄今为止市场上最好的HPC芯片,并将持续一段时间。”MI300A 在 72 x 75.4mm 基板上采用集成散热器封装的设计,适合插槽 SH5 LGA 主板,每块板有 4 个处理器,能有效地控制开发成本。
据介绍,MI300A目前已经开始小批量出货,并且将为今年晚些时候推出的美国新一代200亿亿次的El Capitan超级计算机提供动力。
MI300X:1530亿个晶体管,性能超越英伟达H100
除了MI300A之外,AMD还带来了更为强大的针对针对LLM进行优化的MI300X。
据介绍,MI300X内部集成了12个5/6nm工艺的小芯片(HMB和I/O为6nm),拥有1530亿个晶体管。在内核设计上,采用了相比MI250X更简单的设计,放弃了 APU 的 24 个Zen4内核和 I/O 芯片,取而代之的是更多的 CDNA 3 GPU 和更大的 192GB HBM3内存,带来高达5.2TB/s的带宽和896GB/s的Infinity Fabric带宽。

 、
、
AMD称,MI300X提供的HBM密度是英伟达最新的H100芯片的2.4倍,其HBM带宽最高是H100的1.6倍。更大HMB容量和更高的带宽,使得MI300X减少了CPU和GPU之间的数据移动,这也使得功耗和延迟大大降低,并可以运行比英伟达H100芯片更大的模型。

据苏姿丰介绍,MI300X可以支持400亿个参数的Hugging Face AI模型运行,并在发布会上演示了让这个LLM写一首关于旧金山的诗。这也是全球首次在单个GPU上运行这么大的模型。单个MI300X可以运行一个参数多达800亿的大模型。


AMD还发布了AMD Instinct平台,该平台将八个MI300X GPU组合到一块服务器主板上,提供总计1.5TB的HBM3内存。值得一提的是,该平台采用行业标准OCP设计,与英伟达的专有MGX平台形成鲜明对比。AMD表示,这种开源设计将加快部署速度。

苏姿丰称,MI300X和八个GPU的Instinct平台将在今年第三季度出样,第四季度正式推出。
AMD MI300C和MI300P
据Seminalysis报道称AMD MI300系列其实总共有四种不同的配置,除了MI300A和MI300X之外,还有MI300C和MI300P,尽管不确定这两种配置是否真的会发布。
其中,MI300C采用了96核Zen4+HBM的CPU,以应对英特尔的Sapphire Rapids HBM。然而,市场可能太小,产品太贵,AMD无法生产这个版本。
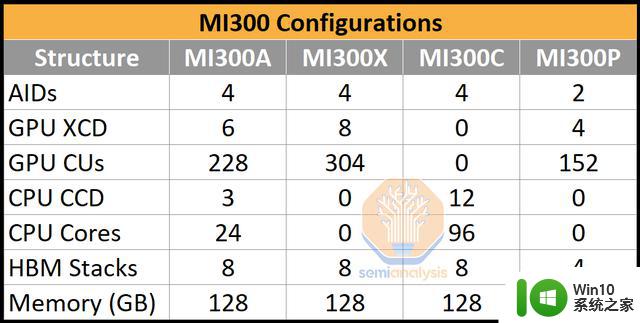
而MI300P就像一个半尺寸的MI300X。这是一个可以在PCIe卡中以较低功率进入的。这同样需要主机CPU进行搭配。但这将是最容易开始开发的版本。
加速软件生态建设
对于AMD来说,其AI加速器在软件生态上非常的孱弱。相比之下,英伟达的CUDA软件已经为其AI加速器构建了一条强大的护城河。
在此次的发布会上,AMD总裁Victor Peng上台谈论了AMD围绕开发软件生态系统所做的努力。

AMD计划在其人工智能软件生态系统开发中执行“Open(software approach)、Proven(AI capability)和Ready(support for AI models)”的理念,Victor Peng则负责该生态系统的开发。
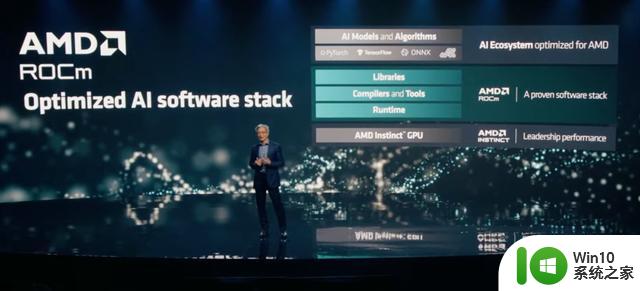

据Victor Peng介绍,AMD已经构建了一套完整的库和工具ROCm,可以用于其优化的 AI 软件堆栈。与英伟达独有的CUDA生态不同,这是一个开放平台。AMD在过去几年来也一直在不断优化 ROCm 套件。同时,AMD还在与很多合作伙伴合作,希望进一步完善其软件生态,方便开发者的AI开发和应用部署。
第四代EPYC处理器Bergamo
除了MI300系列的AI加速器产品之外,AMD在此次发布会上还对第四代EPYC处理器家族进行了更新。包括面向云原生计算的“Bergamo”系列新产品以及代号为Genoa-X的第四代 EPYC 3D V-Cache CPU等。

AMD现有的第四代 EPYC 产品代号为 Genoa,采用 5nm 工艺,支持 PCIe 5.0 及 CXL 扩充技术、支持 DDR5。
据介绍,新一代的AMD EPYC Genoa 在云工作负载中的性能是英特尔竞争处理器的 1.8 倍,在企业工作负载中的速度是英特尔竞争处理器的 1.9 倍。
苏姿丰表示,绝大多数人工智能都在 CPU 上运行,而AMD 的产品在这方面性能方面比竞争对手的Xeon 8490H 具有绝对领先优势,性能高出 1.9 倍,效率也同样是竞争对手的1.8 倍。
新推出的Bergamo处理器则是向云原生计算,采用全新的Zen 4c 内核,最高具有 128 个核心、256 个线程,拥有820 亿个晶体管,兼容 x86 ISA 指令,支持DDR5-4800,可相对满足深度云计算的应用需求。

据介绍,全新的Zen 4c核心,可将每个内核所需的面积减半。AMD分享了一些关于Bergamo架构的数据,包括它的核心+L3缓存面积为2.48平方毫米,比它在与标准Zen 4核心相同的5nm制程节点上实现了面积缩小小35%至3.84mm平方毫米。这也使得去得以容纳8个16核CCD,达到128核的峰值。


值得注意的是,目前AMD仅使用八个Zen 4c小芯片和中央I/O小芯片,而标准EPYC芯片最多使用12个Zen 4小芯片。未来的Zen 4c内核处理器,或许可能会有12个小芯片,达到192个内核。
苏姿丰表示,云原生工作负载是一类快速增长的应用程序,在设计时考虑了云架构,并且可以快速开发、部署和更新。Bergamo作为一款着力于“云计算”的处理器,可提供 AMD 目前最大的 vCPU 运算密度,并可提供“最好的能源效率”、“相比于 AMD 此前的 EPYC 处理器,Bergamo 处理器可最高提升 2.7 倍能源效率,并提供三倍容器数量”。
与Ampere相比,AMD EPYC 97X4处理器具有多达128个内核,可为关键的云原生工作负载提供高达3.7倍的吞吐量性能。此外,带有“Zen 4c”内核的第4代AMD EPYC处理器可为客户提供高达2.7倍的能源效率,并支持每台服务器多出3倍的容器,以最大规模地驱动云原生应用程序。

AMD Bergamo处理器接下来将会直接与英特尔的144核Sierra Forest、Ampre的192核Ampere One处理器相竞争。
此外,AMD还带来了“Genoa-X”EPYC 处理器,采用AMD 3D V-Cache技术,拥有多达96个“Zen4”内核,并带来了行业领先的1.1GB+L3缓存,进一步扩展了AMD EPYC 9004系列处理器,为计算流体动力学(CFD)、有限元分析(FEA)、电子设计等技术计算工作负载提供世界上最好的x86 CPU自动化(EDA)和结构分析。Genoa-X还可以通过每天在Ansys CFX中提供高达两倍的设计工作来显著加快产品开发。
编辑:芯智讯-浪客剑
AMD最强AI芯片挑战NVIDIA:单芯片可处理大模型,晶体管数量达1530亿!相关教程
- 1530亿晶体管芯片发布,AMD正式叫板英伟达,开启全新竞争格局
- 英伟达自己超越自己,H200取代H100成为新的最强AI芯片
- AMD发布会:“最强算力”Instinct MI300X、新款AI PC芯片如期登场
- AI芯片先开挂,AMD要追赶英伟达,谁能在AI市场占得先机?
- 英伟达新款芯片推迟面向中国市场,功能最强大的一款,改良芯片
- 台积电打脸英伟达:AI撑不起芯片大盘,市场对AI芯片的需求降低
- AMD全新AI芯片:颠覆Nvidia垄断,引领人工智能硬件新浪潮
- AI爆火,英伟达GPU芯片利润高达1000%,还供不应求!了解为什么英伟达GPU芯片如此受欢迎
- 英伟达再追单AI芯片,台积电紧急增购封装设备
- 叫板英伟达 AMD斥巨资收购达智通,AMD欲借此成为芯片巨头
- AI力挺美国芯片股创十多年来最佳年度表现,英伟达(NVDA.US)、AMD(AMD.US)最亮眼
- AMD上海研发中心大规模裁员,芯片巨头重塑业务格局
- 全球债市遭抛售,恒指或创新高,马士基业绩超预期
- 高通骁龙8至尊版发布,性能媲美桌面处理器,决胜AI时代的关键!
- 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 一个印度人救了微软,另一个毁了IBM?探讨印度人在科技行业的影响力
微软新闻推荐
- 1 高通骁龙8至尊版发布:二代自研CPU性能逆天,最强AI更像真人
- 2 英特尔AMD史诗级合作,捍卫X86生态:两大巨头联手,颠覆传统CPU格局
- 3 微信消失在桌面了,怎么找回 微信桌面快捷方式消失怎么恢复
- 4 打印机的纸怎么放进去 打印机纸盒放纸技巧
- 5 onedrive开始菜单 Win10如何设置Onedrive开启和使用
- 6 台式电脑如何连接打印机设备打印 台式电脑如何设置本地打印机
- 7 惠普笔记本win11移动硬盘怎么用 win11系统移动硬盘插入后不显示
- 8 微软称每天有超过15000条恶意QR码信息被发送到教育目标,如何有效应对?
- 9 win10系统电脑没有wifi选项 Win10无线网络不显示解决方法
- 10 win7能看见的文件夹win10看不到 win7可以访问win10但win10无法访问win7
win10系统推荐
- 1 系统之家ghost win10 64位稳定家庭版下载v2023.06
- 2 系统之家win10 64位旗舰破解版v2023.06
- 3 雨林木风ghost win10 32位家庭版正版v2023.06
- 4 雨林木风ghost win10 32位官方安装版v2023.06
- 5 电脑公司ghost win10 32位精简优化版v2023.06
- 6 电脑公司ghost win10 64位官方安全原版v2023.06
- 7 深度技术ghost win10 32位最新破解版v2023.05
- 8 电脑公司win10 64位旗舰安全版v2023.05
- 9 电脑公司ghost win10 32位免费安装版v2023.05
- 10 萝卜家园ghost windows10 32位稳定游戏版下载v2023.05
系统教程推荐
- 1 蜘蛛侠:暗影之网win10无法运行解决方法 蜘蛛侠暗影之网win10闪退解决方法
- 2 win10玩只狼:影逝二度游戏卡顿什么原因 win10玩只狼:影逝二度游戏卡顿的处理方法 win10只狼影逝二度游戏卡顿解决方法
- 3 U盘装机提示Error 15:File Not Found怎么解决 U盘装机Error 15怎么解决
- 4 《极品飞车13:变速》win10无法启动解决方法 极品飞车13变速win10闪退解决方法
- 5 window7电脑开机stop:c000021a{fata systemerror}蓝屏修复方法 Windows7电脑开机蓝屏stop c000021a错误修复方法
- 6 win10桌面图标设置没有权限访问如何处理 Win10桌面图标权限访问被拒绝怎么办
- 7 win10打不开应用商店一直转圈修复方法 win10应用商店打不开怎么办
- 8 无线网络手机能连上电脑连不上怎么办 无线网络手机连接电脑失败怎么解决
- 9 win10错误代码0xc0000098开不了机修复方法 win10系统启动错误代码0xc0000098怎么办
- 10 笔记本win10系统网络显示小地球只有飞行模式如何恢复 笔记本win10系统网络无法连接小地球图标灰色